Automate EBS Snapshot using AWS Lambda
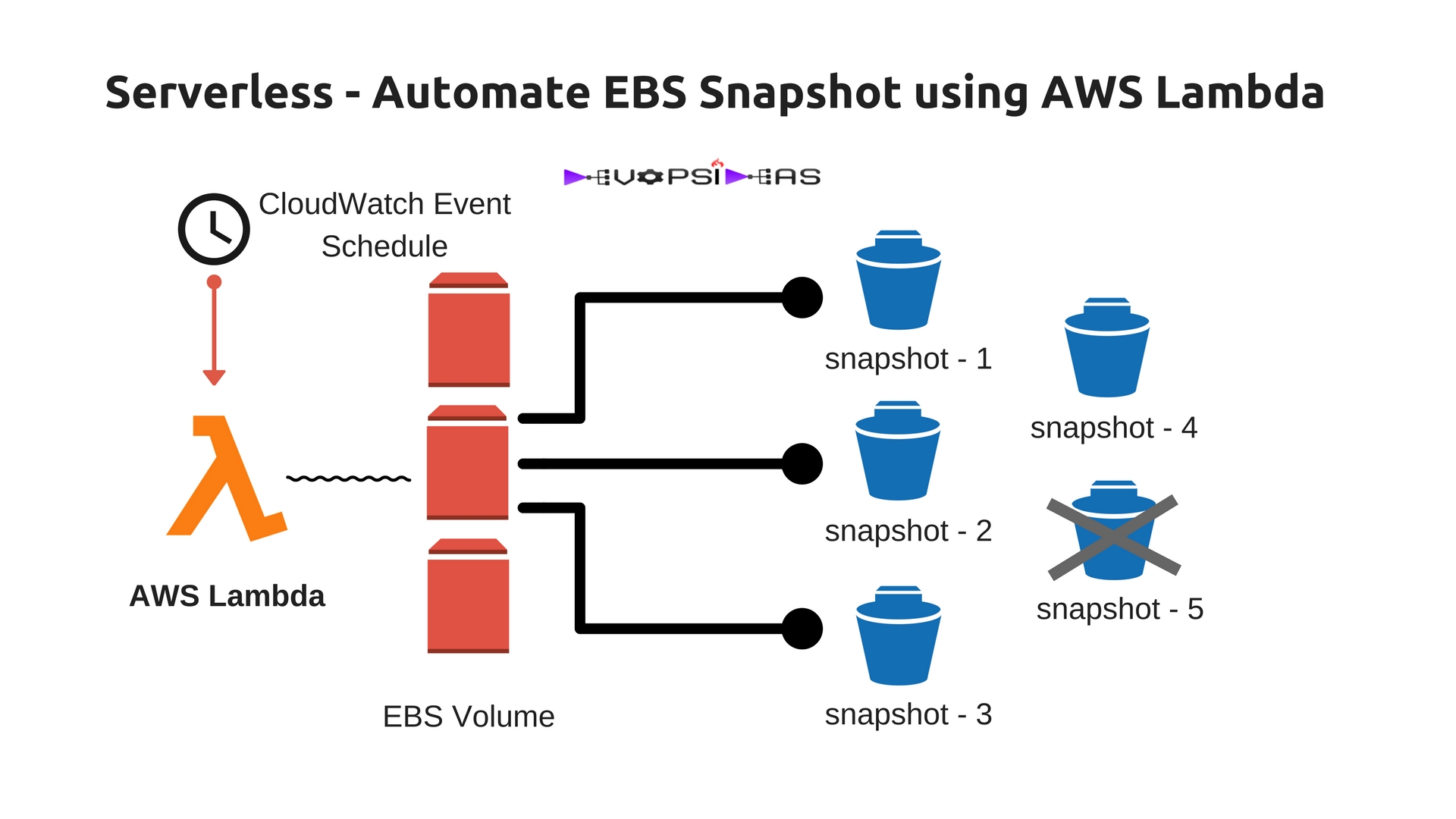
In this article we will see a realtime example of serverless architecture by automating EBS Snapshot using AWS Lambda.
What is Serverless? Does it mean there are no servers?
It does not mean there are no servers involved. Rather serverless means developers don’t have to think about the servers. Some key features of serverless are,
-
- You offload responsibility to someone else you trust.
-
- You don’t need to provision resources based on load (like IaaS)
-
- Don’t need a lot of planning effort ( On Premise )
-
- Growing the app happens on-demand
AWS Lambda
AWS Lambda is an implementation of FaaS ( Function as a Service ). This makes the serverless architecture possible where we can execute our logic by creating functions without the need to worry about the server that runs it.
Lambda is a fully managed compute platform.
-
- You can Run code without thinking about servers
-
- It Executes on AWS infrastructure
-
- Event-driven computing
-
- It’s Stateless
Completely Automated Adminstration
-
- High availability and Fault Tolerance
-
- Scales up and down depending on the demand
-
- Server and operating system maintenance
-
- Logging and monitoring
Resource Allocation
Lambda allocates CPU Power, Network Bandwidth, Disk I/O. You need to allocate Memory and Execution time.
Lambda Limits
-
- The maximum time a function can run is 5 mins.
-
- Memory – Minimum = 128 MB / Maximum = 1536 MB (with 64 MB increments). If the maximum memory use is exceeded, function invocation will be terminated.
-
- It is stateless and hence you cannot store data that you want to be persistent. You need to handle it by storing it either in s3bucket or using other storage options.
-
- It supports Java, NodeJS and python
EBS Snapshot using AWS Lambda
In this we will be implementing a lambda function to create snapshots of running EC2 instances by specifying a tag name. We will also remove snapshots which are older than some days which got created using this function to save cost.
We will do the following things,
1. Create an IAM role with necessary permission to perform the operation. This will be assigned to the lambda function that we will create
2. Python script with logic to create and delete snapshots.
3. Create a Lambda function and configure events schedule to trigger this function
Create an IAM role
Create an IAM role for lambda with the following permissions,
1. Retrieve information about volumes and snapshots from EC2
2. Take new snapshots using the CreateSnapshot API call
3. Delete snapshots using the DeleteSnapshot API call
4. Write logs to CloudWatch for debugging
Go to IAM > Policies > Create policy. Copy the below policy in the JSON tab and click Review policy. Give a name for the policy ( eg, lambda_ebs_snapshot ) and click Create policy
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:*"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Effect": "Allow",
"Action": "ec2:Describe*",
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"ec2:CreateSnapshot",
"ec2:DeleteSnapshot",
"ec2:CreateTags",
"ec2:ModifySnapshotAttribute",
"ec2:ResetSnapshotAttribute"
],
"Resource": [
"*"
]
}
]
}
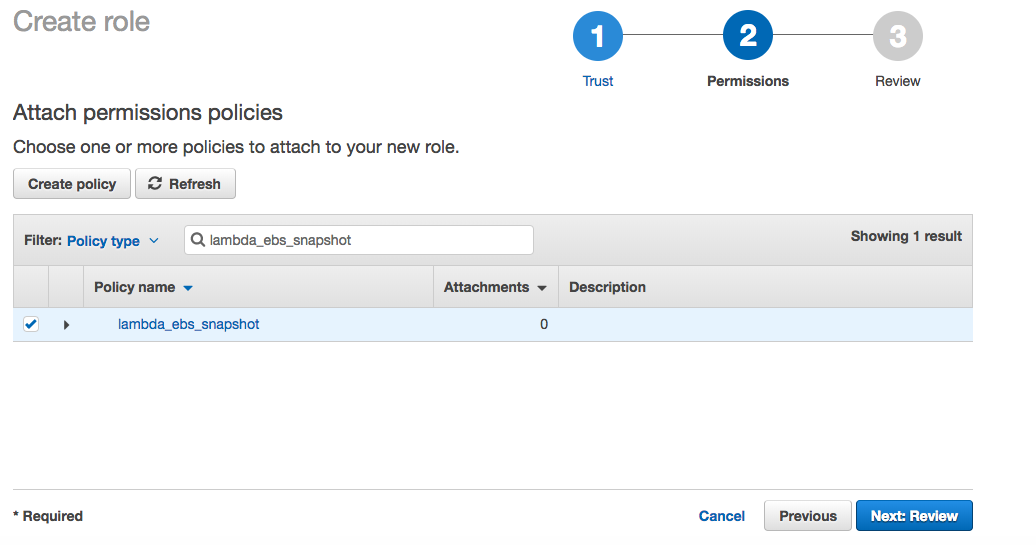
In the AWS management console, go to IAM > Roles > Create Role. Select Lambda and click Next. In the attach permissions policies, select the policy which we created above and click review.
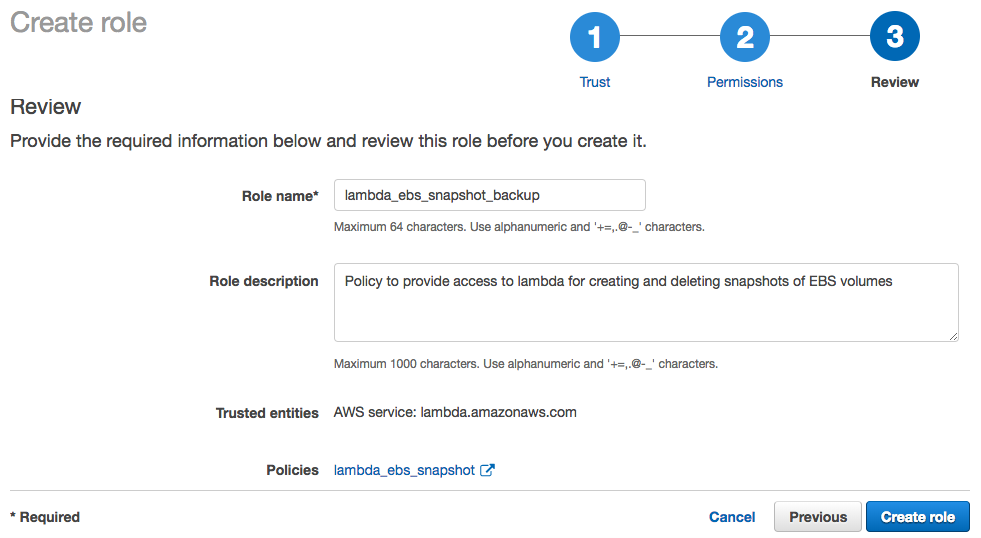
Next, give the role a name. Eg – lambda_ebs_snapshot_backup and a short description about the role (optional) and click Create Role
Python script to create and delete snapshot
The below python script will create snapshot of all running instances. It’ll also delete snapshot which are older than the days specified in retention_days variable. You can also pass this as Lambda Environment variable.
import boto3
import boto3
import datetime
import pytz
import os
ec2 = boto3.resource('ec2')
def lambda_handler(event, context):
print("\n\nAWS snapshot backups starting at %s" % datetime.datetime.now())
instances = ec2.instances.filter(
Filters=[{'Name': 'instance-state-name', 'Values': ['running']}])
for instance in instances:
instance_name = filter(lambda tag: tag['Key'] == 'Name', instance.tags)[0]['Value']
for volume in ec2.volumes.filter(Filters=[{'Name': 'attachment.instance-id', 'Values': [instance.id]}]):
description = 'scheduled-%s.%s-%s' % (instance_name, volume.volume_id,
datetime.datetime.now().strftime("%Y%m%d-%H%M%S"))
if volume.create_snapshot(VolumeId=volume.volume_id, Description=description):
print("Snapshot created with description [%s]" % description)
for snapshot in volume.snapshots.all():
retention_days = int(os.environ['retention_days'])
if snapshot.description.startswith('scheduled-') and ( datetime.datetime.now().replace(tzinfo=None) - snapshot.start_time.replace(tzinfo=None) ) > datetime.timedelta(days=retention_days):
print("\t\tDeleting snapshot [%s - %s]" % ( snapshot.snapshot_id, snapshot.description ))
snapshot.delete()
print("\n\nAWS snapshot backups completed at %s" % datetime.datetime.now())
return True
Script walkthrough:
The function begins by importing boto3, datetime, and pytz. Line 5 defines an ec2 resource, used to filter through our instances. The lambda_handler begins on line 8; line 9 simply prints that the AWS snapshot has begun, and provides the time in which it started. Line 10 goes through our EC2 instances and filters them by whether or not the instance is running. This then begins a loop (12) to pull each instance name, filtered by using a Python lambda (not AWS Lambda) function. The function then loops through the instances’ volumes (line 15)
Line 19 begins the process of trying to create a snapshot by taking the volume and performing the create_snapshot operation. It prefixes the snapshot name with the tag “scheduled-“. This tag will be used while removing older snapshots. It prints the snapshot that has been created.
Line 22 begins an optional function that removes snapshots older than days specified as part of retention_days environment variable. Snapshot names that starts with ‘scheduled-‘ will be removed. This is where pytz is used to help with timezones.
Finally, on line 27, the function prints the snapshot that has been created and the time it was completed.
Installing script dependencies:
The above script uses pytz for which we need to install the dependencies before importing it to lambda. To do this, copy the above content in a file named lambda_function.py and follow the below steps.
# mkdir /tmp/lambda_tmp # mv lambda_function.py /tmp/lambda_tmp/ # pip install pytz -t l/tmp/lambda_tmp/ # cd /tmp/lambda_tmp # zip -r9 ~/lambda_EBS.zip *
We will be using this zip file that contains the python script along with the dependencies while configuring the lambda function
Create the Lambda Function for snapshot
In the Lambda console navigate to Functions > Create Function -> Author from scratch. Give the lambda function a name eg, ebs_backup. In the Role section, select Choose an existing role and then select the role (lambda_ebs_snapshot_backup) which we created in the first step and click Create Function.
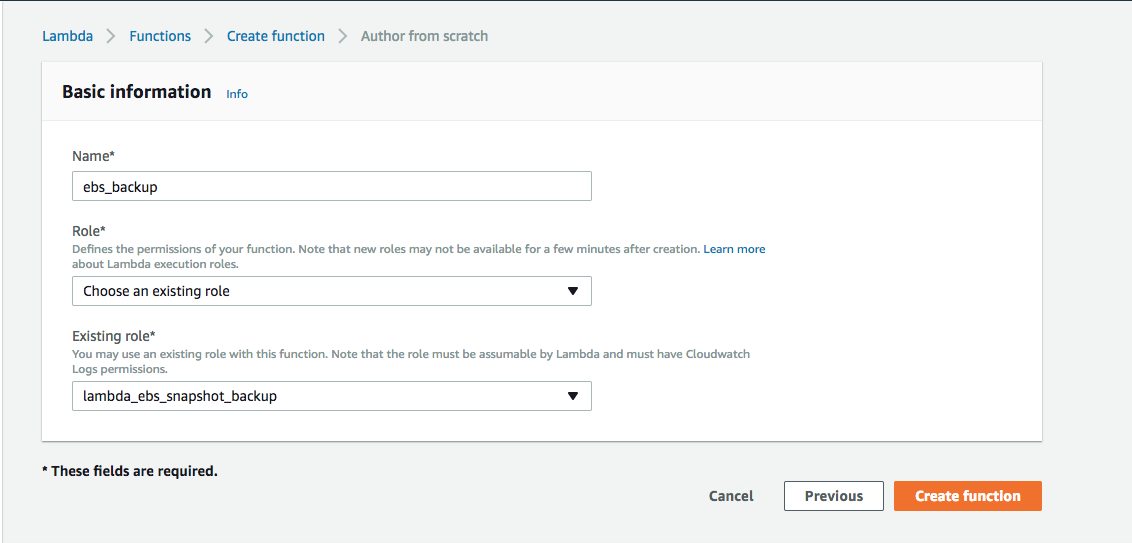
In the next step, we need to define the function. Select Upload a .ZIP file in the Code Entry type. Select Python 2.7 for Runtime option. Upload the zip file which we created in the previous step that contains the script along with its dependencies.
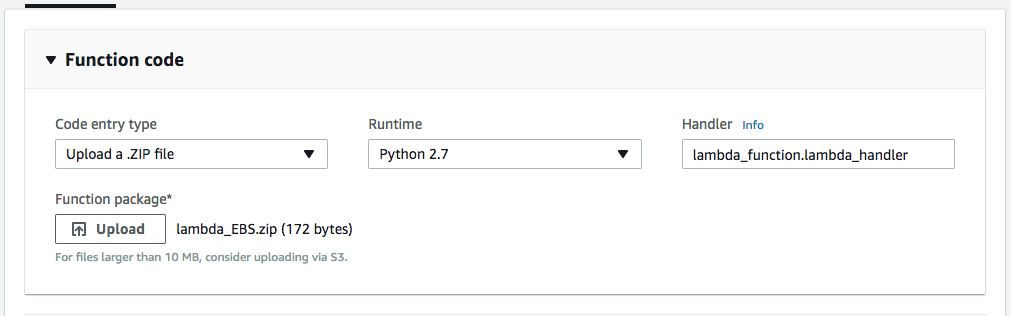
Next, we need to specify the snapshot retention period in order to delete old ones. We can do this by using Environment variables
In the next step, you can define the execution time of this function and memory needed. The default timeout is 3 seconds which is too short for our task. We can change it to 1 min or more. The default memory size is 128MB which should be sufficient for this.

Click Save to save the function
Testing the function
Now that we have everything in place, its time to test the function. Click on Test. You’ll be asked to configure a test event. For this example, we can just go with the Hello World template. Give the test event a name and click create.
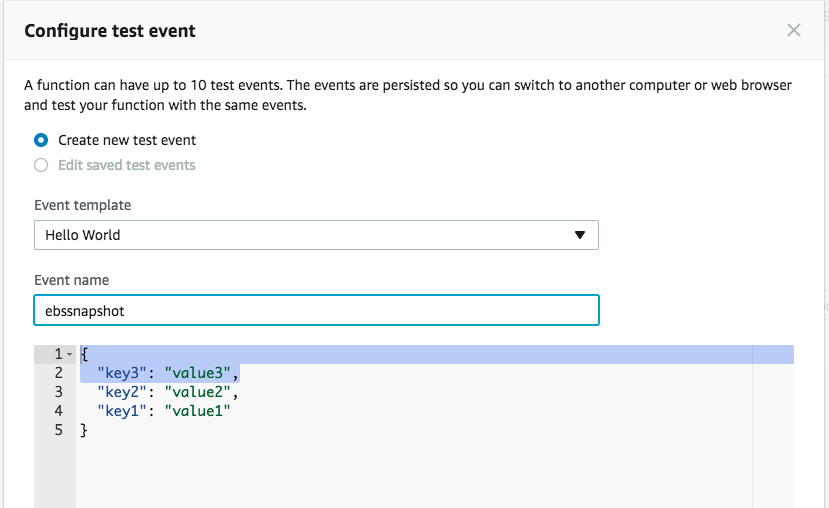
Now Click Test again. If everything goes well, you’ll receive a “Execution result: succeeded” message. Note: Running this test will take EBS snapshots of the EC2 instances that are running.
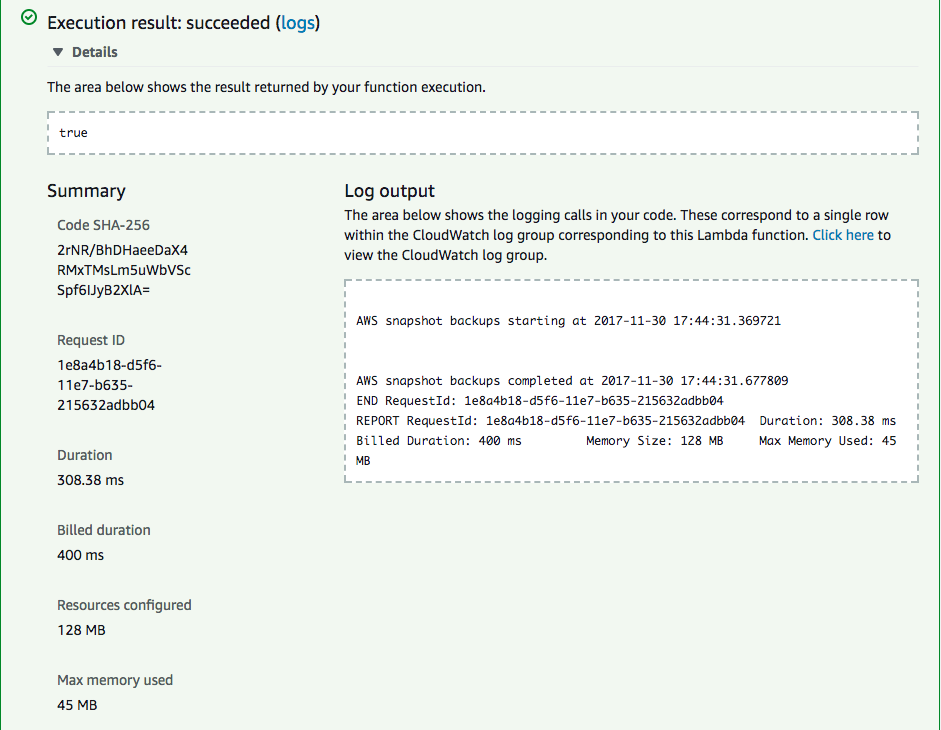
Creating an event function
Now that we have tested our function, we can schedule it to run on daily basis. We need to configure Cloudwatch Events – Schedule to make it run at scheduled interval. In the ebs_backup function page that we create, select Triggers > Add trigger
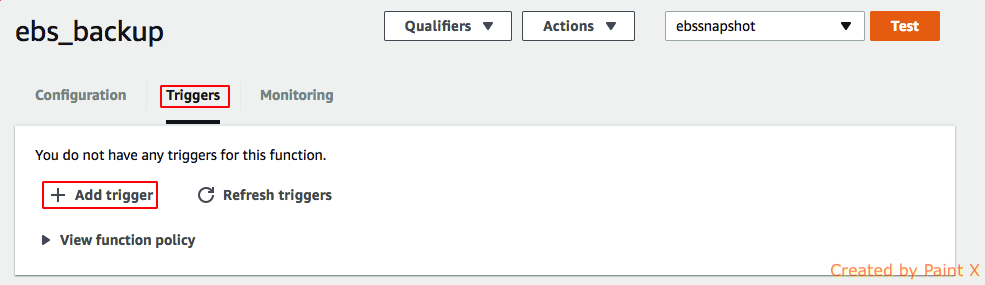
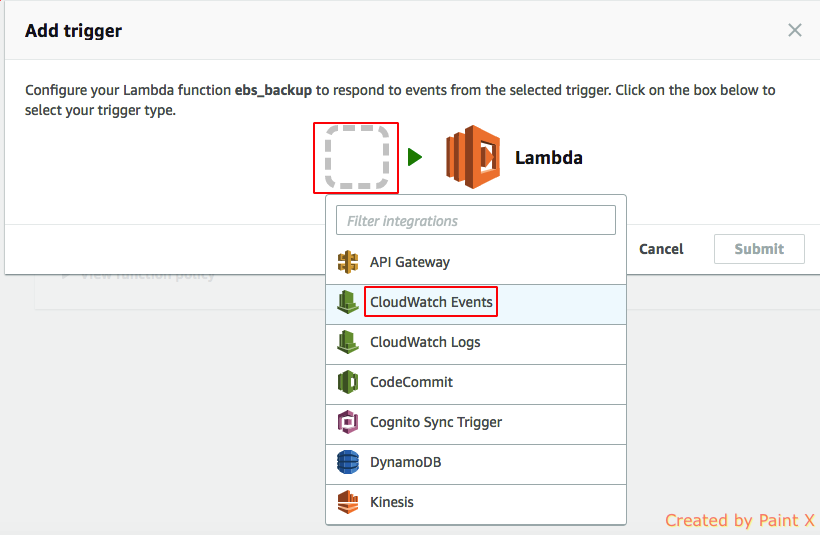
Click on the box and select CloudWatch Events
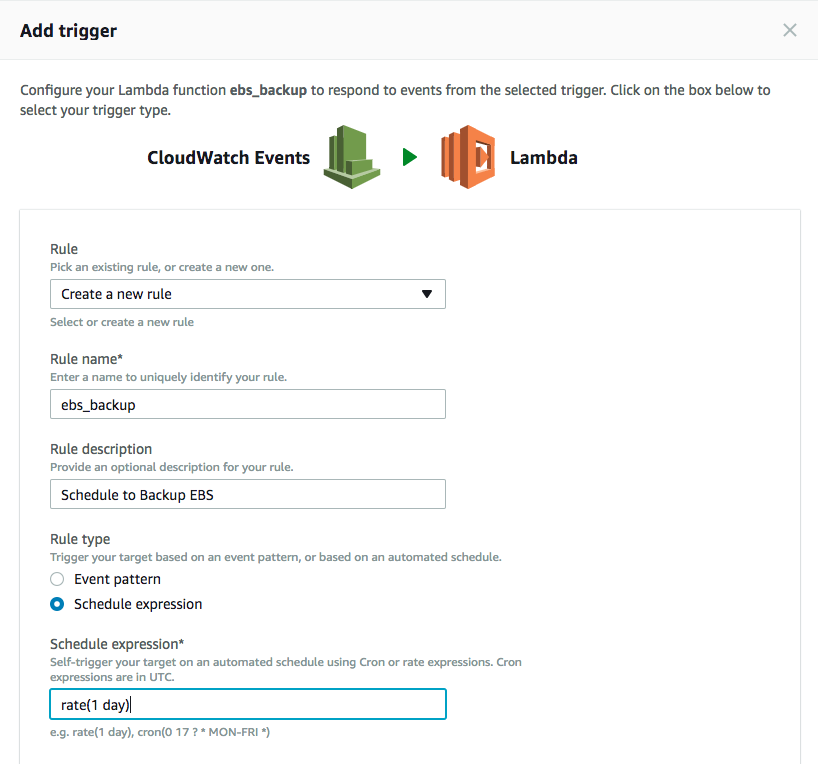
In the next page, provide a rule name, description and the schedule expression and click Submit. Note that the cron expressions are in UTC.
Above implementation is a basic example of serverless architecture. The script takes backup of EBS only in the region where it is run from. You can enhance it further to take snapshots of volumes attached to specific instance, covering all regions etc.