
In this article we will learn what are some operational challenges in microservices architecture and how consul helps to overcome it. With this we will learn what a service mesh is and how consul helps to overcome the challenges it creates.
Monolithic Architecture:
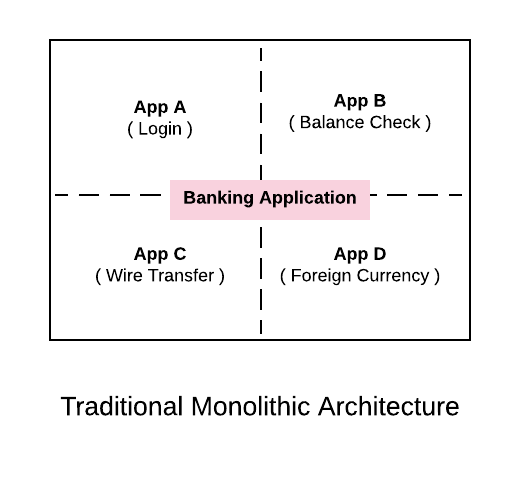
A classic monolith is a single application that we deploy but typically has multiple discrete sub components. For example, if we are delivering a desktop application for banking, from the diagram above we can say sub system A is used for Login, sub system B for checking balance, sub system C for doing wire transfer and sub system D for foreign currency.
Even though the sub systems provide independent functions, we are delivering and packaging the application as single monolithic app. We deploy everything as a single unit.
Challenges with monolithic architecture:
The major challenge with this approach is that for example, if we have to fix a bug in one of the sub system eg. balance check, we cannot just fix that specific sub system and just change it. We have to co-ordinate with all the other groups and re-deploy it again as a single unit.
Microservices Architecture
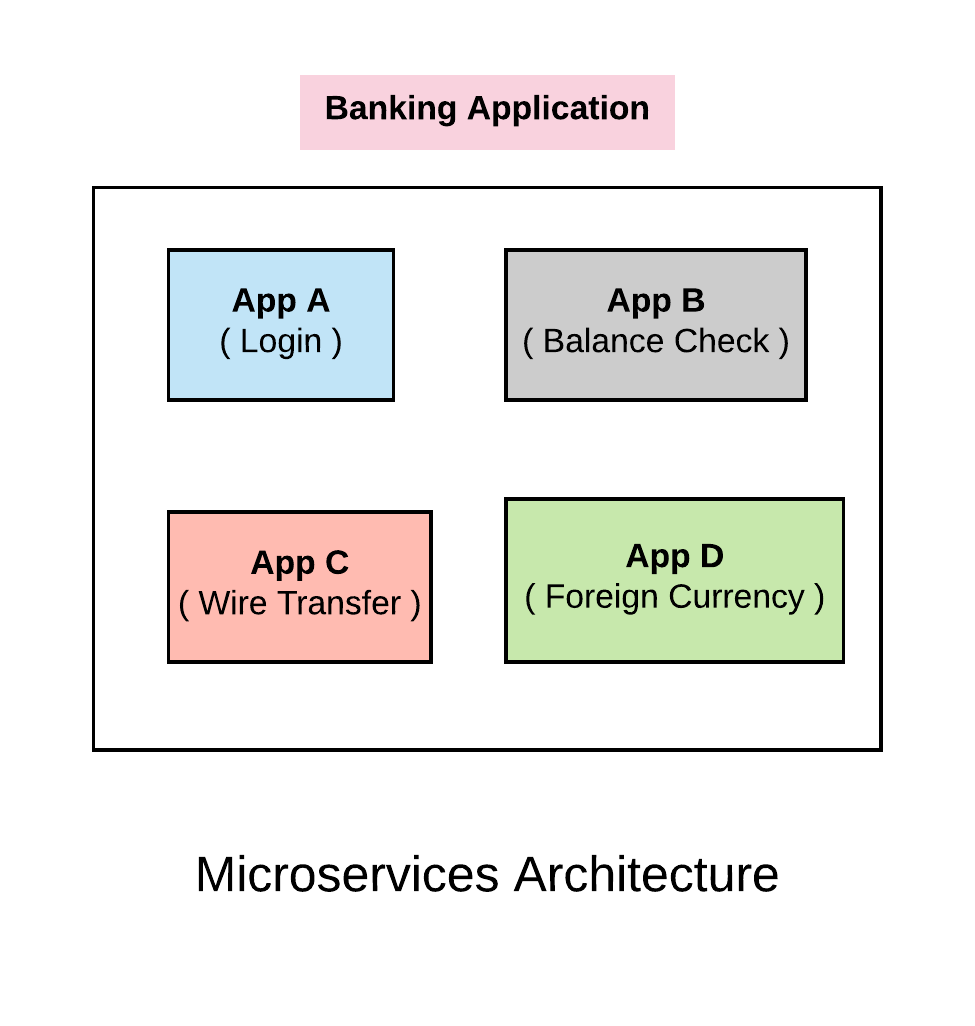
In microservices, we deploy each of the sub system as discrete services. In this way if we have a bug in one of the sub system, we just need to patch and redeploy that specific sub system without having to co-ordinate across the different systems. This sort of architecture buys us a set of development agility. We don’t need to co-ordinate our development efforts across many different groups. We can develop independently and deploy whenever we want without having to depend on other systems. For example App A can deploy on daily basis, App C can deploy on quarterly basis etc.
This approach is great for development teams but it also brings in other set of challenges. What we have gained in development efficiency brings in some operational challenges for us.
Challenge 1: Discovery
The most immediate challenge we face in microservice is, Discovery.
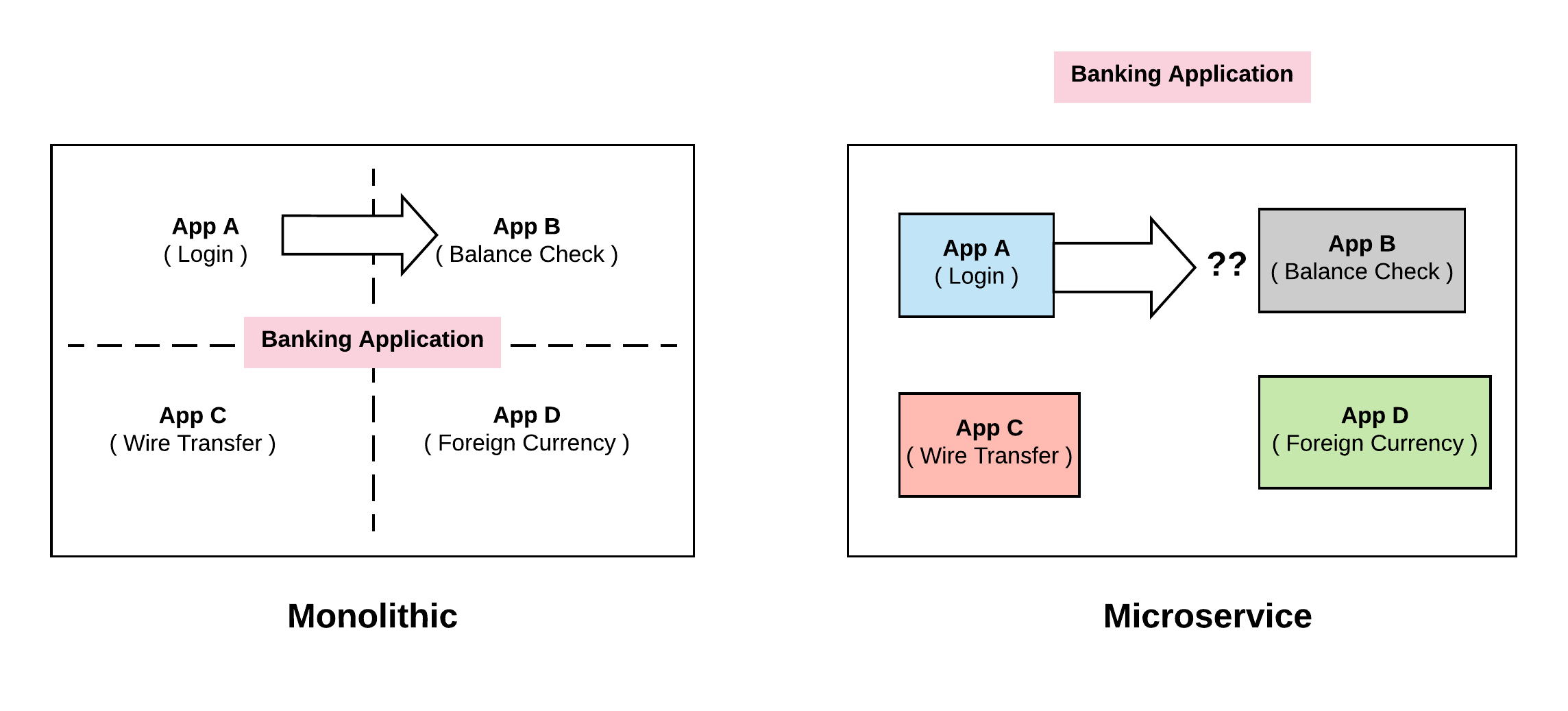
Let’s say, service A wants to call service B. The way we would traditionally do is, service B would expose a method and mark it as public and then service A can call it. In the same application (monolithic) it is just a function call.
All this changes when we come to distributed world ( Microservices ). App A and B are no longer running in the same machine and they are not part of the same application. Service A has no idea where Service B is running. This first level problem is what will call discovery. How do these different pieces discover one another.
There are few approaches to overcome this.
Using Load Balancer:
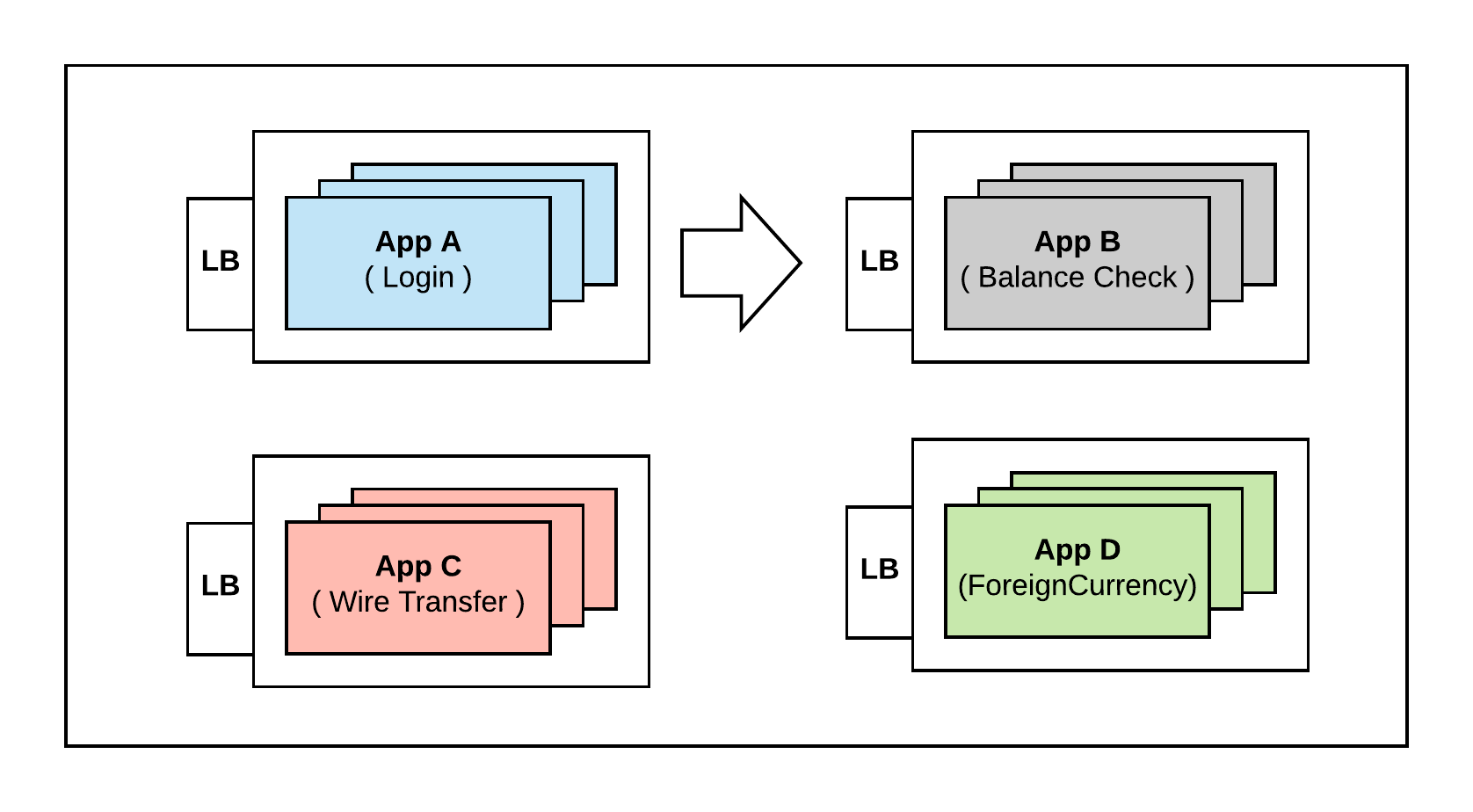
Historically what we would have done is to put a load balancer in front of all these services and then hardcode the IP address of those Load Balancers. So Service A calls Service B using the hardcoded IP of the load balancer and the Load Balancer will in turn routes the request to one of the members running Service B. This allows A to skip the discovery by hardcoding the address but introduces few problems.
Problems with the above approach:
– The first problem is, now we have proliferation of load balancers. These are representation of additional costs and maintenance
– We have introduced single point of failure all over our infrastructure. Even though we are running multiple instances of service B for availability, A is hardcoding the Load Balancer IP. If we lose the Load Balancer it doesn’t matter if there are multiple instances of B, effectively the whole service has gone offline.
– We are doubling the latency by introducing new hop
Using Central Registry:
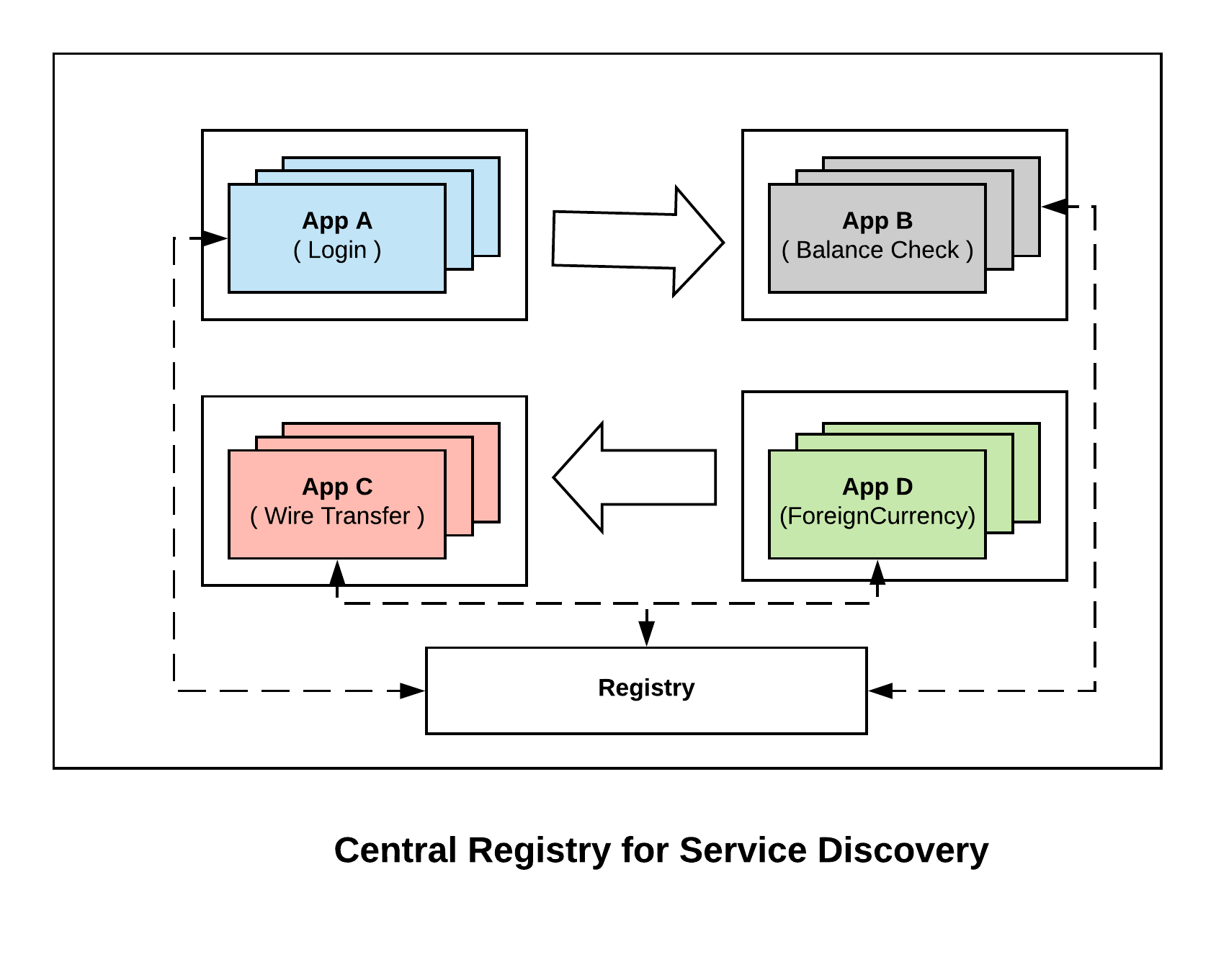
By using a central registry, when each of the instance for a service boot they get registered as part of the central registry. Now when A wants to connect to B, it queries the registry and gets the list of upstream instances for B. Now instead of going through a load balancer, Service A can directly connect to service B. Now if one of the instances of B dies, the central registry picks that up and avoids returning that to service A. So we get the same ability of load balancers to route around failures without actually needing a load balancer.
This simplifies doing service oriented architecture at scale. Consul offers central registry for service discovery.
Challenge 2: Configuration
The second biggest challenge that we run into is configuration.
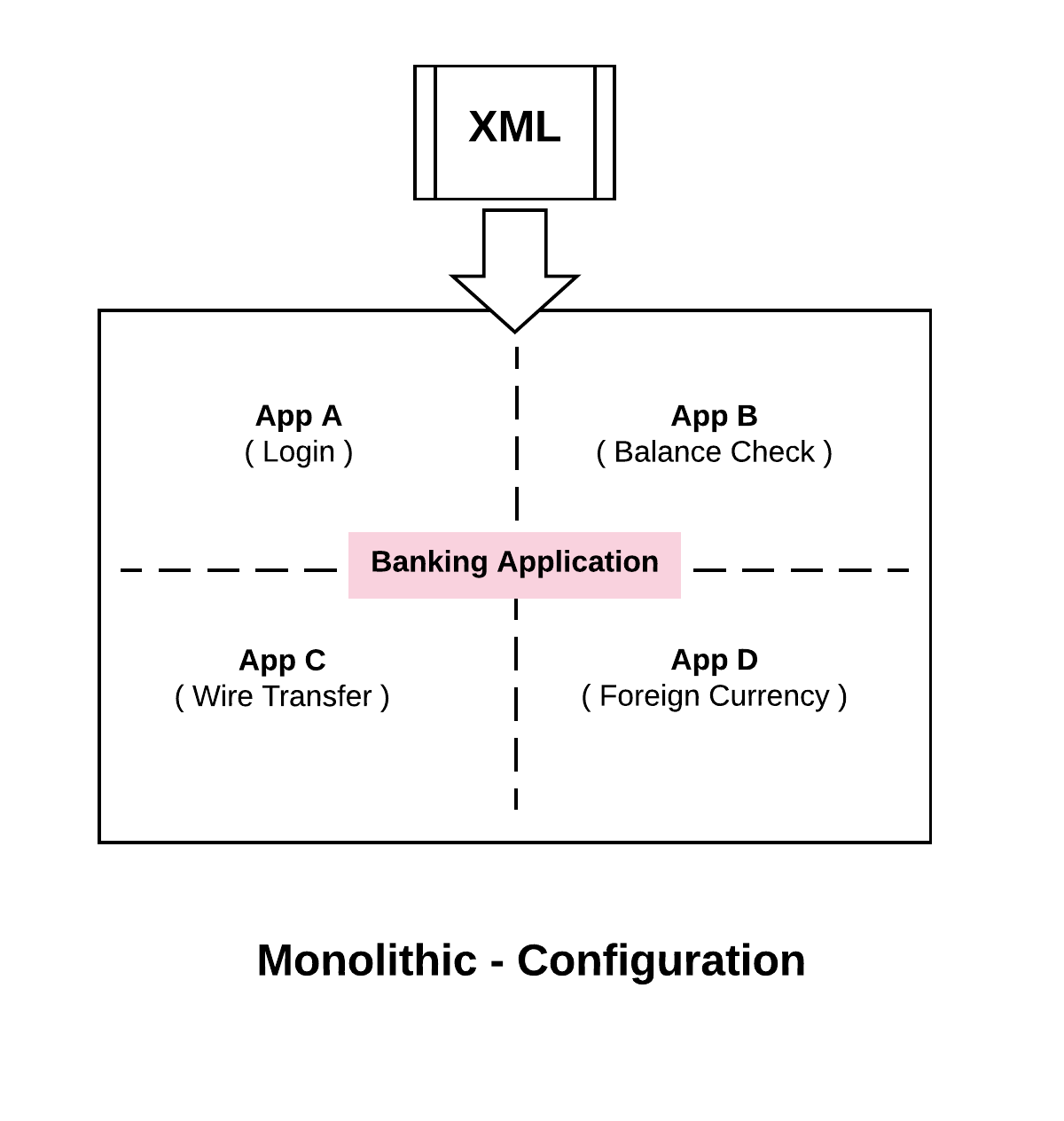
When we take a look at the monolithic architecture, what we would probably have is a giant XML file that will configure the whole thing . The advantage of this is that all the sub systems and all of the components will have a consistent view of the configuration. As an example, suppose we want to put our application in maintenance mode, we want to prevent it from writing to the database so that we could do some upgrades in the background. To do this, we would make some changes to the XML configuration file and all of the sub systems would believe that we are in maintenance mode simultaneously.
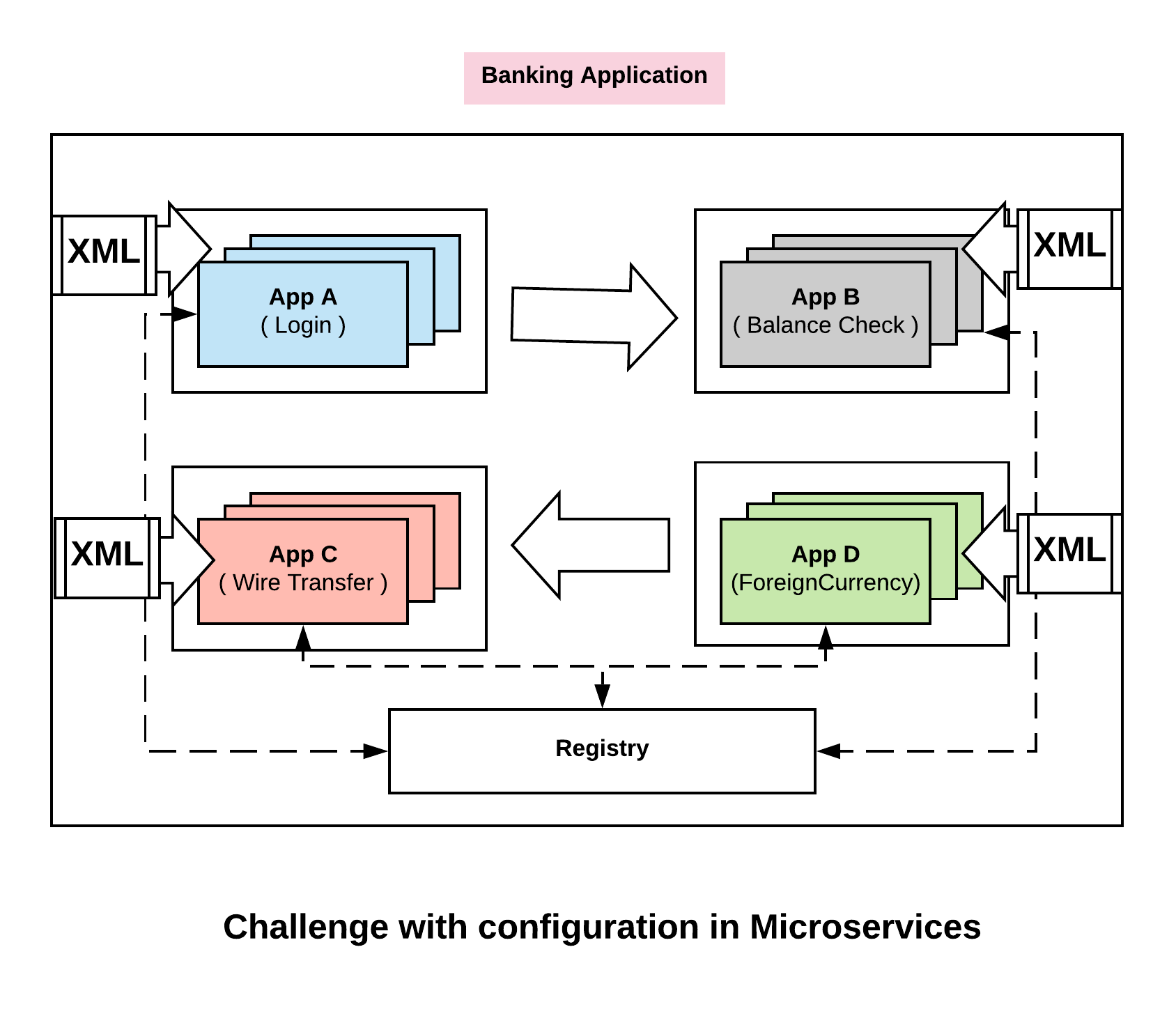
Unlike application configuration in monolithic, configurations in microservices are distributed. Every one of these applications has a slightly different view of what our configuration as a whole is. So we have a challenge here – which is, how we think about configuration in a distributed environment. Let’s see how Consul overcomes this challenge.
Using KV store:
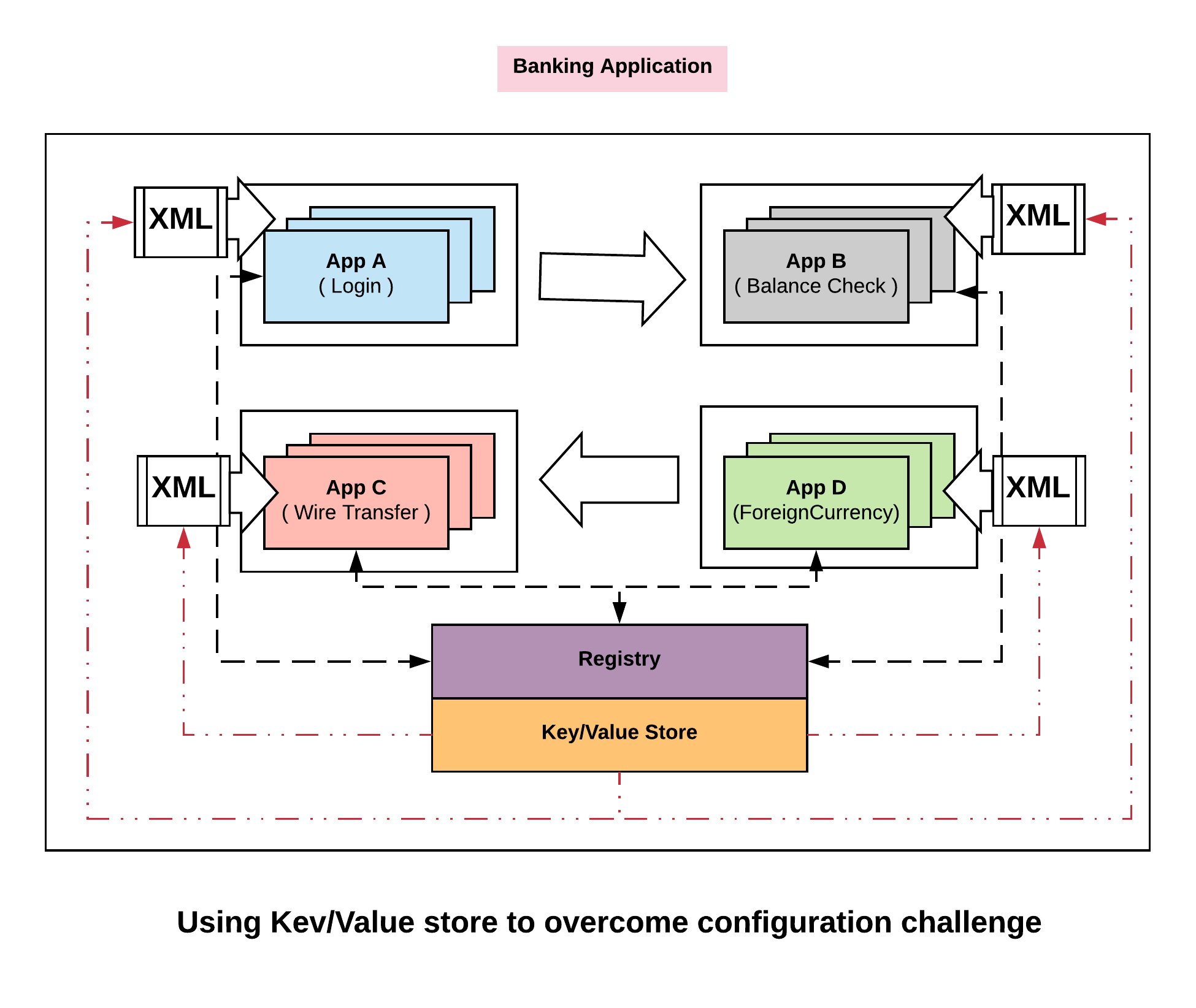
The way Consul thinks about this problem is, instead of trying to define configuration in many individual pieces distributed throughout our infrastructure, we can capture it in a central Key Value store. So we define a key centrally that says, are we in maintenance mode. We then use it to push it out to the edge and then configure the configurations (xml file in this case) dynamically. So now we can change the key centrally for ‘are we in maintenance mode’ from False to True. We can then push that out in real time to all our services giving them a consistent view.
Challenge 3: Segmentation
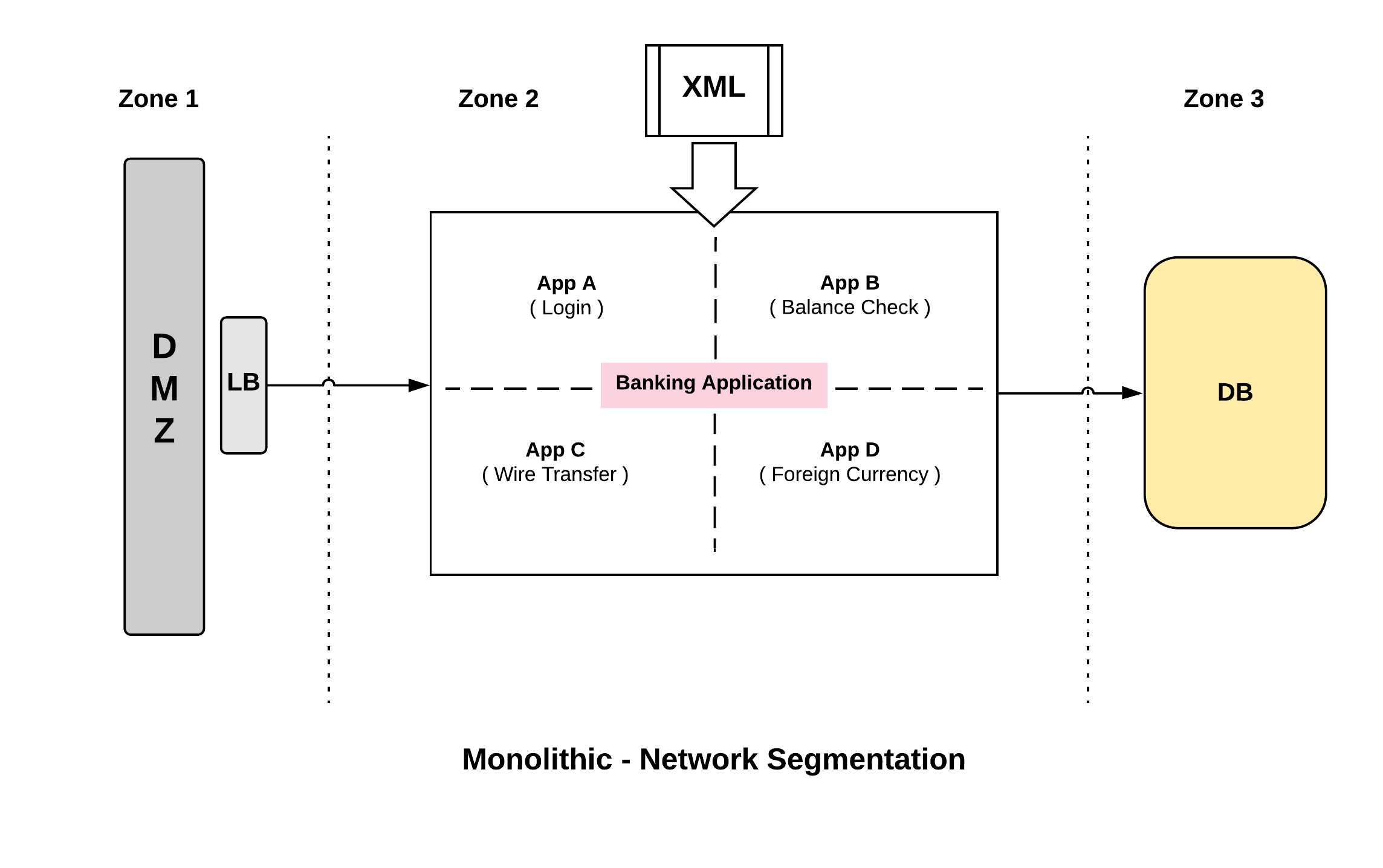
When we look at the classic monolithic architecture, we would divide our network traditionally into three different zones. Zone1 would be the Demilitarized zone where traffic from public internet gets in. Zone2 would be the application zone which receives traffic from DMZ’s. Zone3 would be the Data Zone. So only the Load balancer in Zone1 can reach the application in Zone2 and only the applications running in Zone2 can access the Data Zone hosted in Zone3. So we have a pretty simple three tiered zoning system that allows us to segment our network traffic.
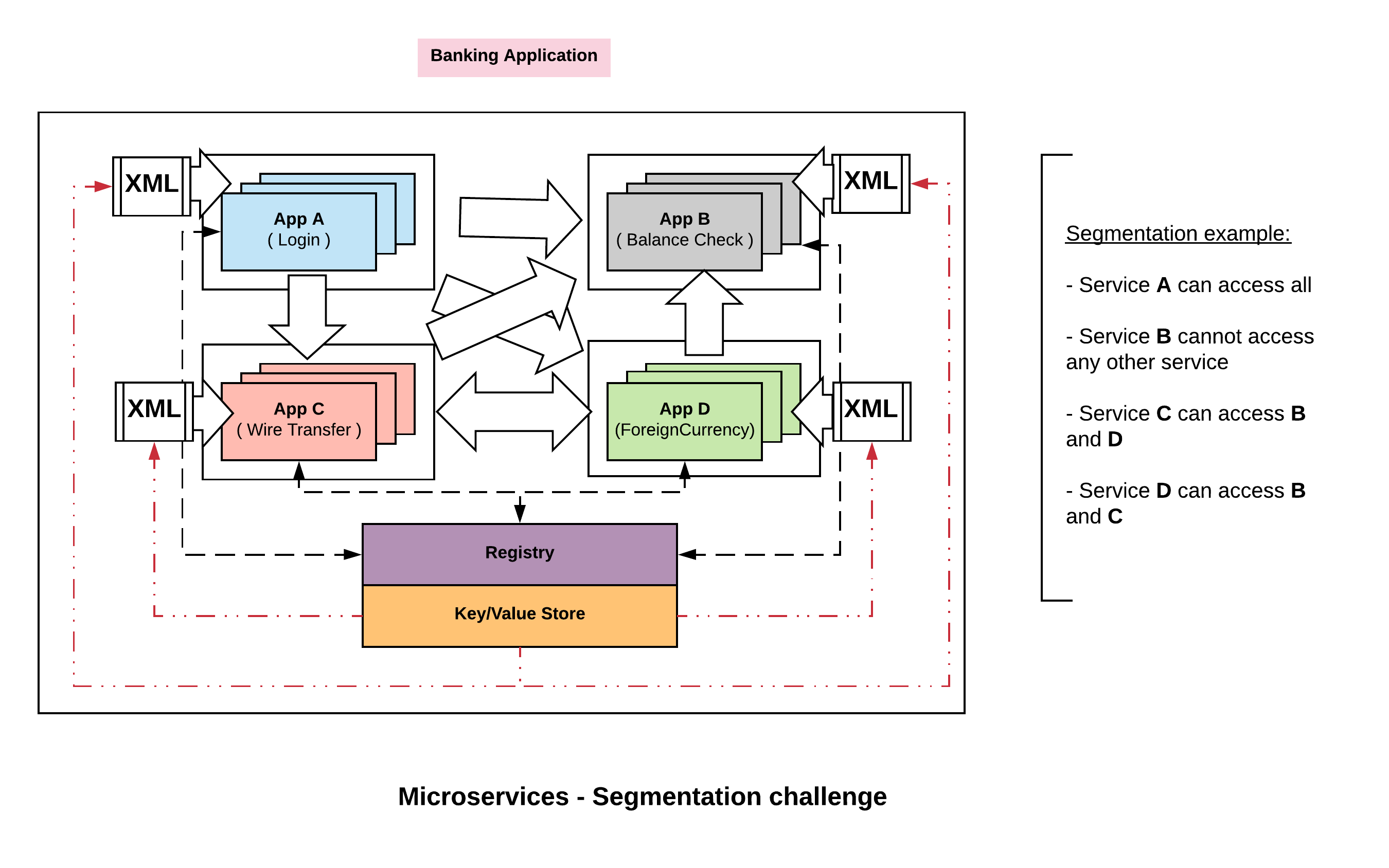
On the other hand when we move to microservices architecture, the pattern has changed dramatically. There is no longer single monolithic application within our zone but many hundred thousands of unique services within the application zone. The challenge is, the traffic pattern is much more complicated now. Many of the services have north south east west traffic flow, its no longer sequentially from load balancer to the application server to the database.
Traffic might come into, lets say mobile banking app or desktop banking app or to API’s through multiple front doors depending on the access pattern. Then each of those services communicate with each other in a complex east west traffic flow. So, the third level challenge becomes how do we think about segmenting this network. How do we partition which services are allowed to talk to which other services.
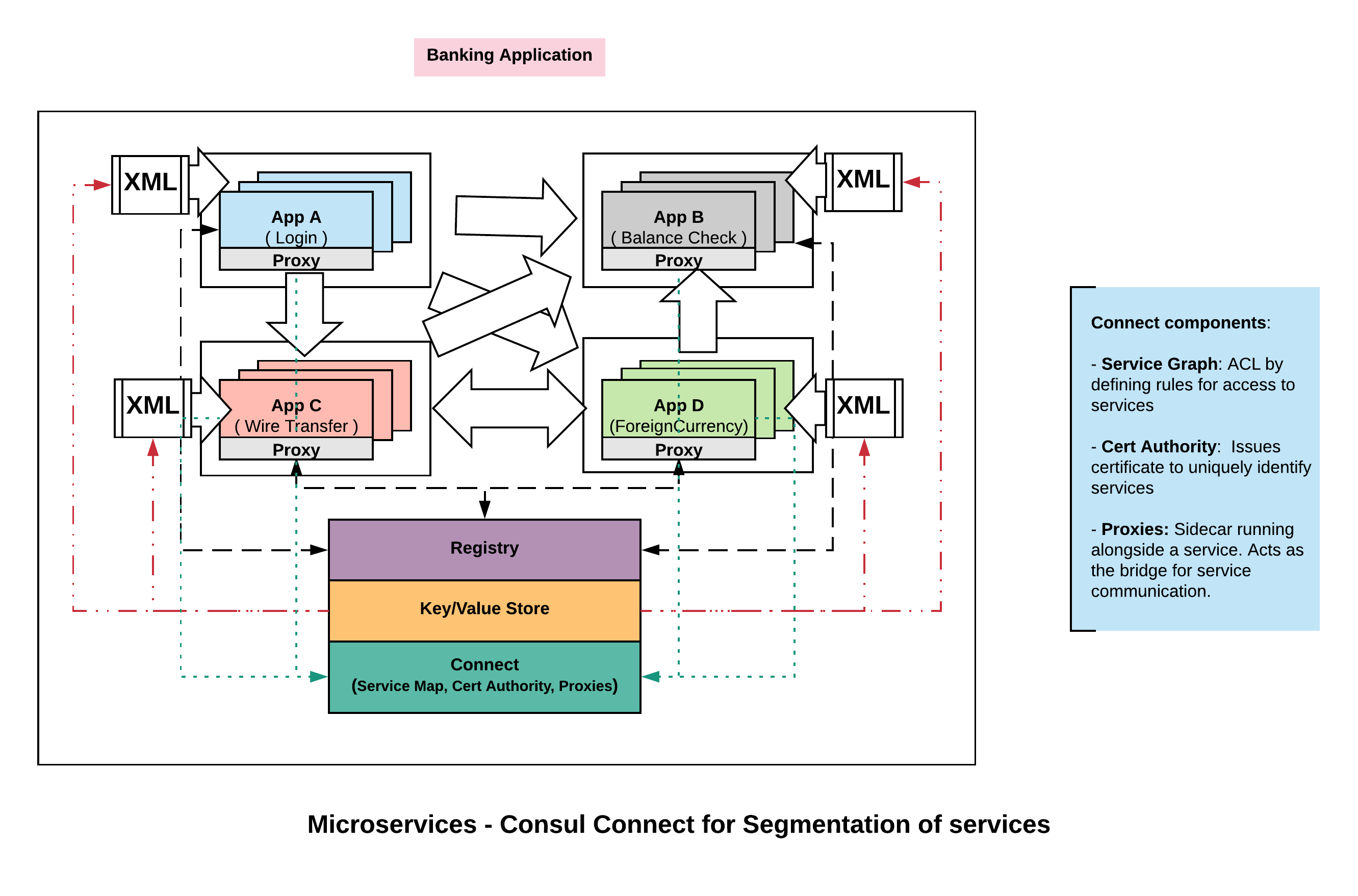
Consul deals with this challenge with a feature called, ‘Connect‘ again by centrally managing the definition around who can talk to who. This starts with few different components.
Service Graph:
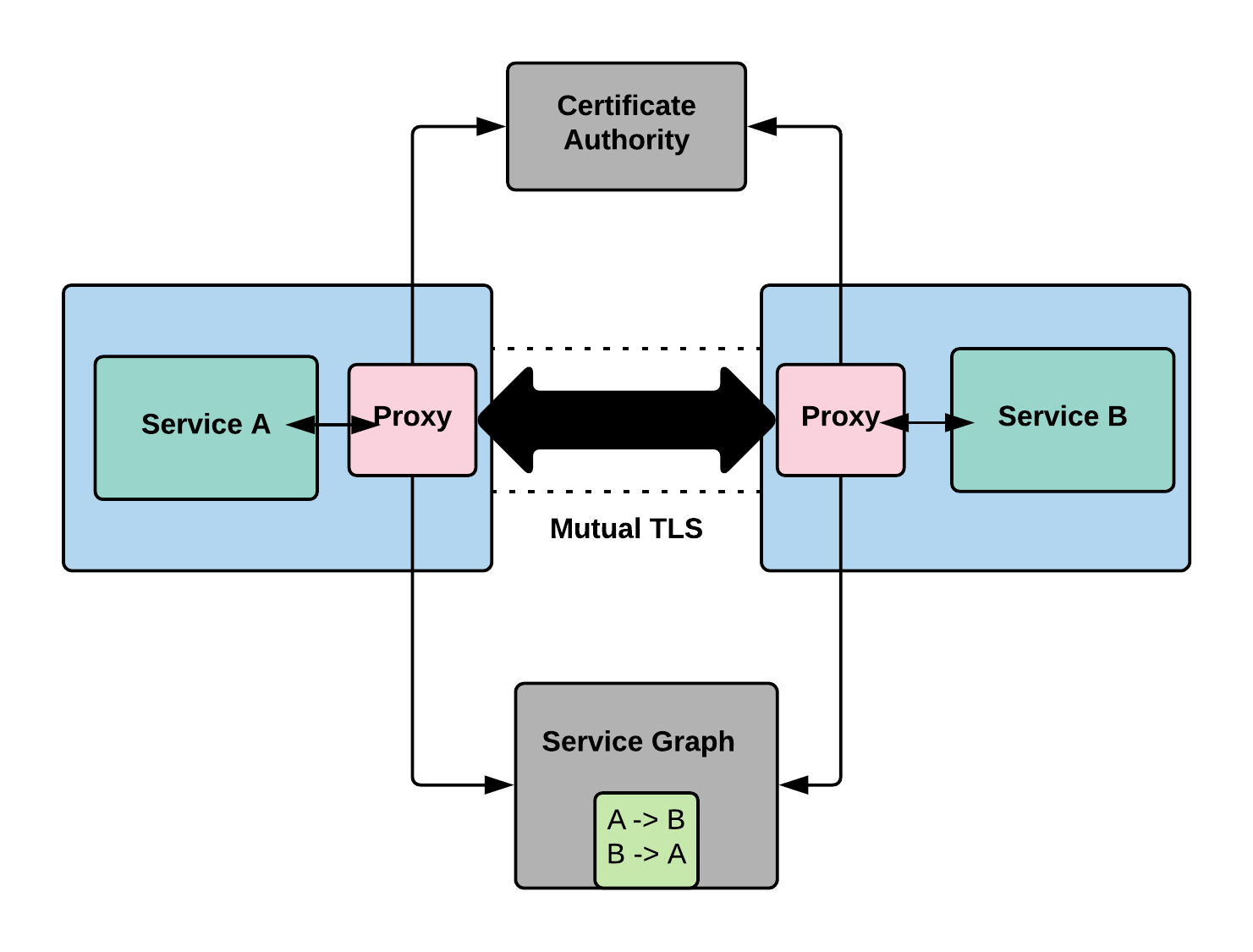
Using service graph, we can define at the service level who can communicate. For eg, we can say A can communicate with B, B with C, C with B, etc. If you take a closer look, we are not talking about IP to IP communication like IP1 can connect to IP2. We are talking about service A can talk to service B at the service layer. The nice thing about expressing at this layer is that the rule is scale independent.
What this means is, if we want our web service to talk to our database service, that might simply be expressed as Web -> DB as a rule. For eg, if we had to translate this to the equivalent firewall rules say we have 50 web servers and 5 databases , that translates to 250 different firewall rules. The scale independent indicates, irrespective of the number of services we add or remove it remains the same. Where as the firewall rule on the other end are the opposite. They are very much scale dependent and tied to the management unit which is an IP.
Certificate Authority:
When we say service A can talk to service B, how do we know what is service A and what is service B. This is done using TLS certificates. Consul issues TLS certificates that uniquely identifies the services.
We enforce the above two approaches by using proxies. The way we end up implementing the access control is through mutual proxying. On a box we might have service A running and on the same box we might have a proxy running alongside of it ( more like a side car ). Similarly for service B, it runs on its own machine or container and it also has a sidecar proxy. Now when A wants to talk to B, it communicates transparently through proxy running in B which terminates the connection and in turn hands it to the actual service.
This approach has few different advantages. First, we are not modifying the code of A and B. The proxies on the other hand are using the certificate authorities to verify the validity of each of the service that is calling upon.
The second advantage of this method is that now we have established encrypted channel between them. The communication between the services takes place through Mutual TLS. This is becoming increasingly important as we talk about regulations like GDPR. Through this we are achieving encryption of data during transit.
Conclusion
With this we have seen how consul can be used to overcome the operational challenges that might arise in a SOA or microservices architecture. The challenges that we discussed – Service discovery, Configuration and Segmentation are collectively referred to as a service mesh. Consul provides this service mesh capability for microservice or service oriented architecture to work.

