
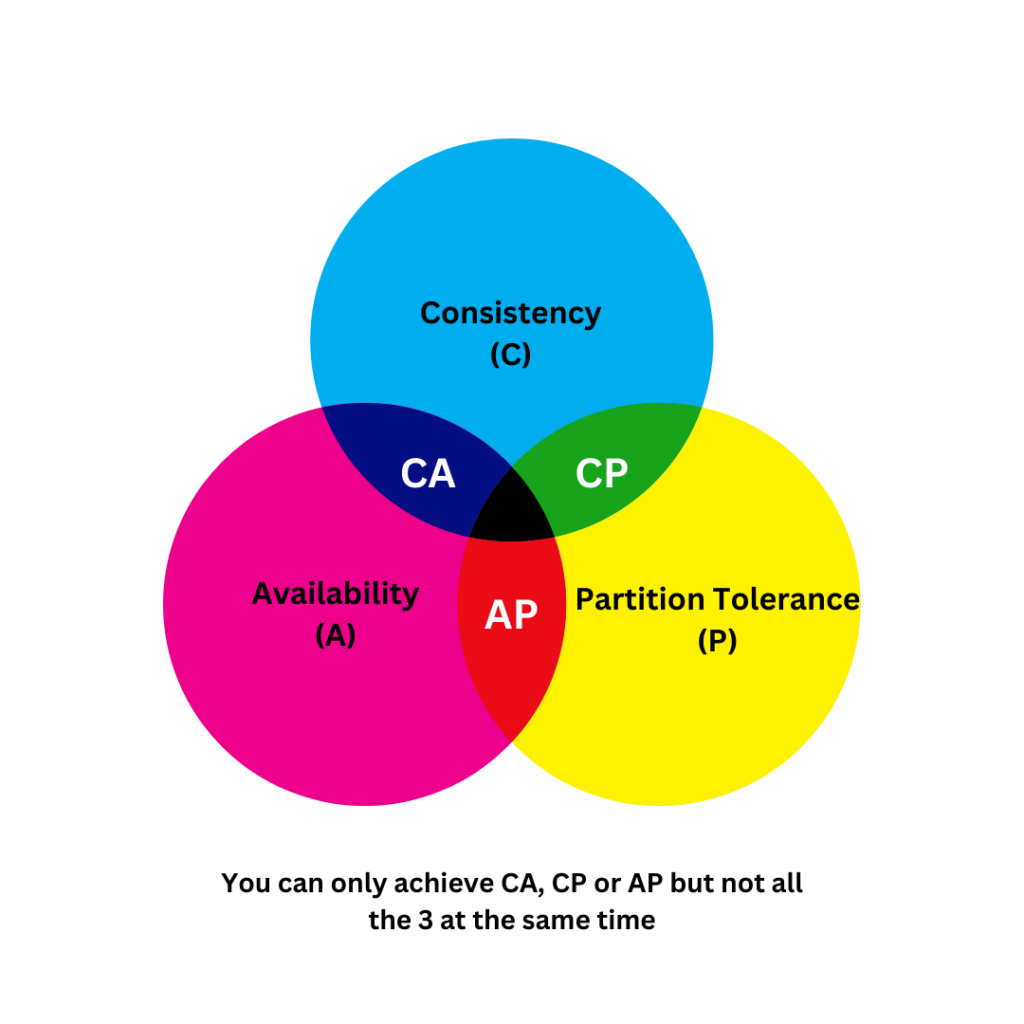
In the world of distributed systems, the CAP theorem (also known as Brewer’s theorem) is a key principle. It essentially states that a distributed data store can only achieve two out of the following three guarantees simultaneously:
- Consistency (C): Every read receives the most recent write or an error.
- Availability (A): Every request receives a (non-error) response, without the guarantee that it contains the most recent write.
- Partition Tolerance (P): The system continues to operate despite an arbitrary number of messages being dropped or delayed by the network between nodes.
So, how do these play out in real-world systems, and why do you need to choose between them? Let’s break it down.
A Simple Analogy
Imagine you’re running a group of online stores, and each store is a node in your distributed system. These stores need to stay in sync, handle customer orders, and continue operating even when things go wrong. But here’s the catch—you can only excel in two out of three areas: staying perfectly consistent, being always available, or continuing to operate despite communication issues between stores. That’s where the CAP theorem comes into play.
Breaking Down the CAP Theorem
1. Consistency (C)
- Definition: All nodes (or stores) see the same data at the same time. When you update something in one store, all other stores should immediately reflect that change.
- Example: Suppose a customer updates their shipping address at Store A. With consistency guaranteed, Stores B and C immediately reflect that change so that the customer doesn’t accidentally ship their package to the wrong address.
2. Availability (A)
- Definition: Every request gets a response, even if it’s not the most up-to-date data. Essentially, the store always stays open for business.
- Example: Even if Store A is experiencing network issues, customers can still place orders at Stores B and C, but the information might not be fully synchronized.
3. Partition Tolerance (P)
- Definition: The system remains operational despite communication breakdowns between nodes (stores).
- Example: If there’s a network issue between Store A and Store B, both stores should still operate independently, processing orders and serving customers as usual.
The Trade-offs: You Can’t Have It All
In reality, distributed systems can’t fully achieve all three aspects (Consistency, Availability, and Partition Tolerance) at once. You’ll need to prioritize two at the expense of the third, depending on what’s most critical for your business. In practical terms, partition tolerance is usually a requirement, so systems often have to choose between consistency and availability. Let’s explore a few scenarios:
Scenario 1: Prioritizing Consistency and Availability (CA)
In this case, you ensure that all stores always have the latest information and are always operational. However, if there’s a communication breakdown between stores (a partition), your system might stop accepting new orders until everything is back in sync.
- Example: Traditional relational databases before distributed systems became common, where consistency and availability were prioritized, but a network partition would cause issues.
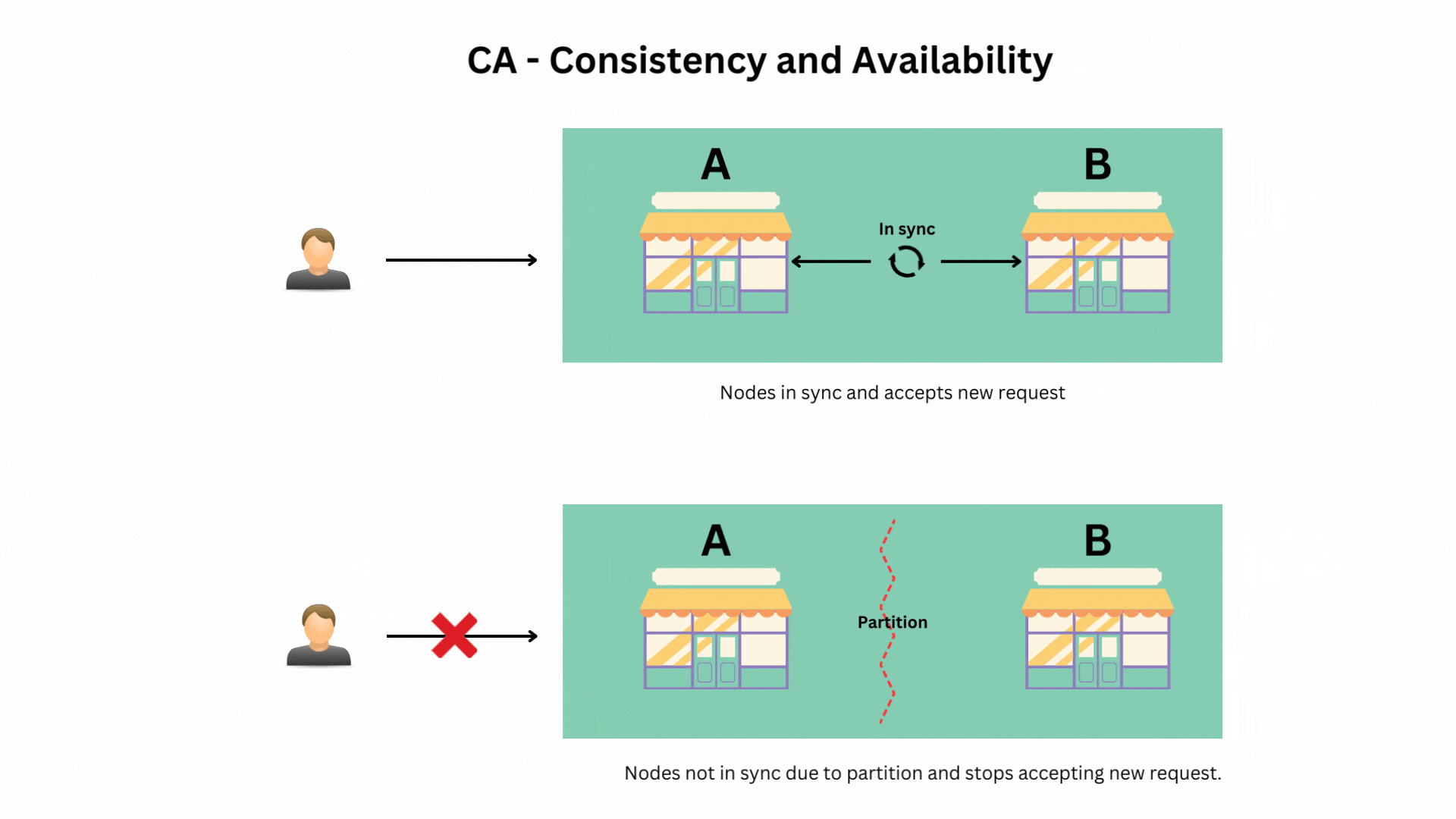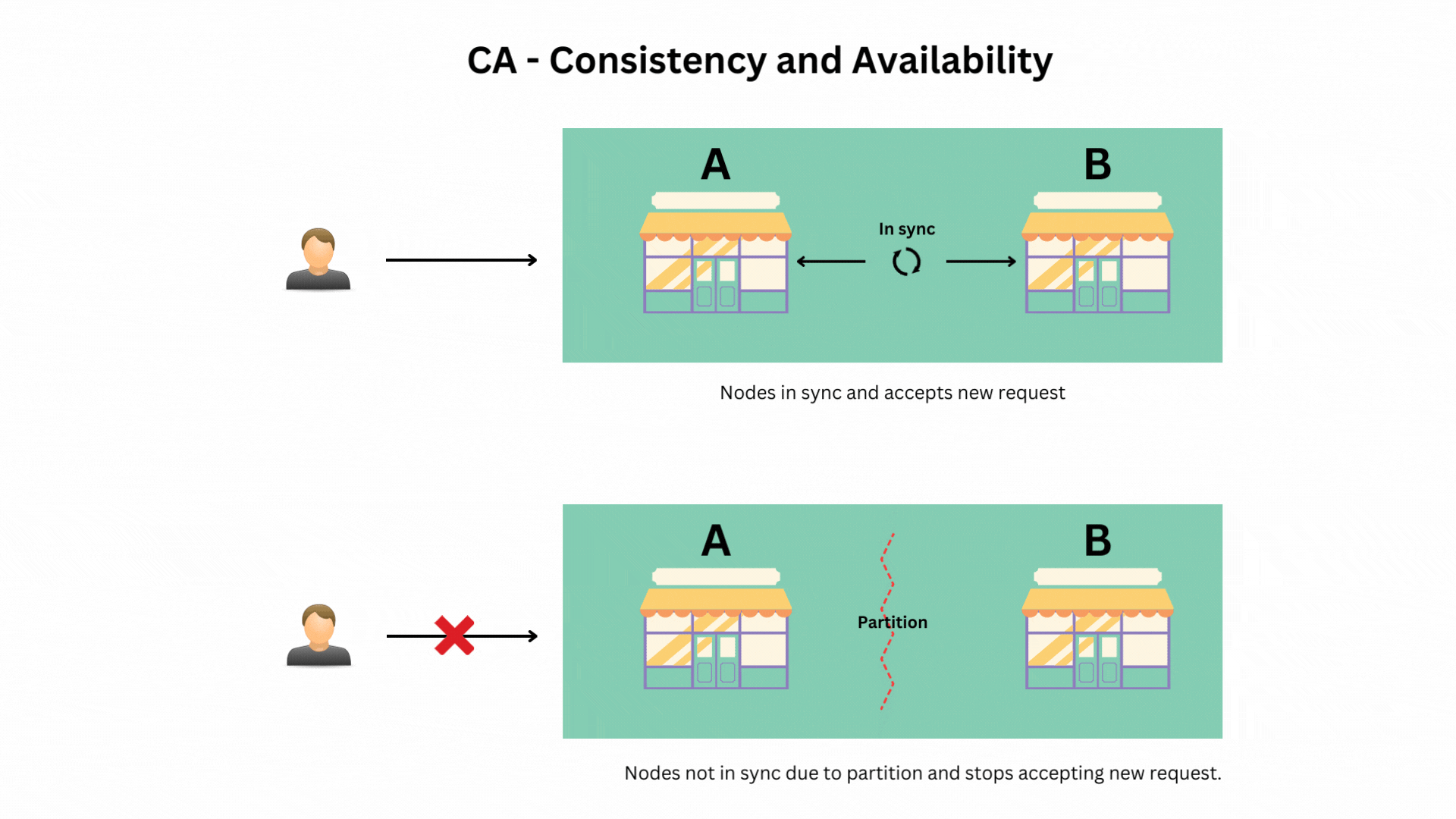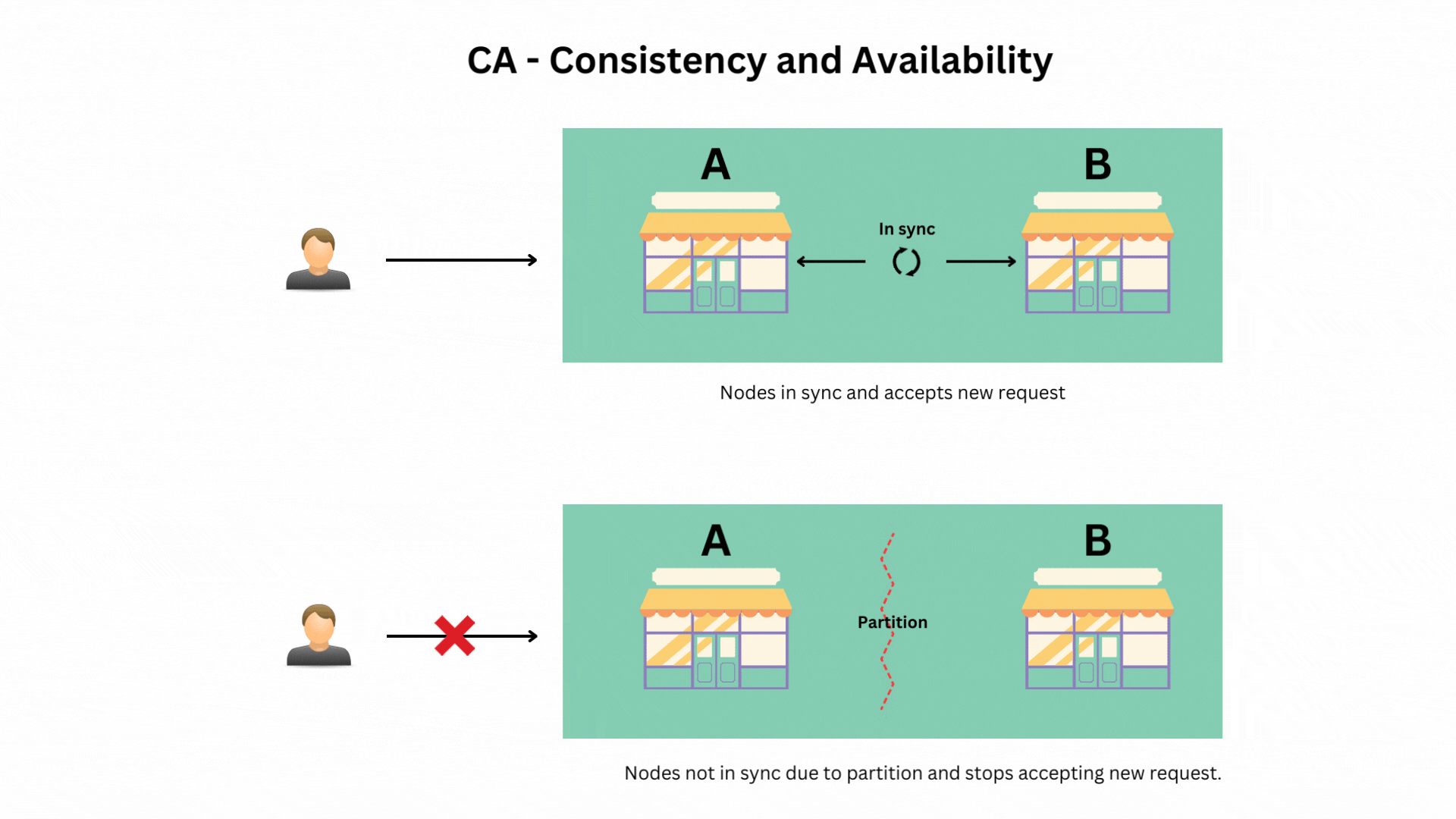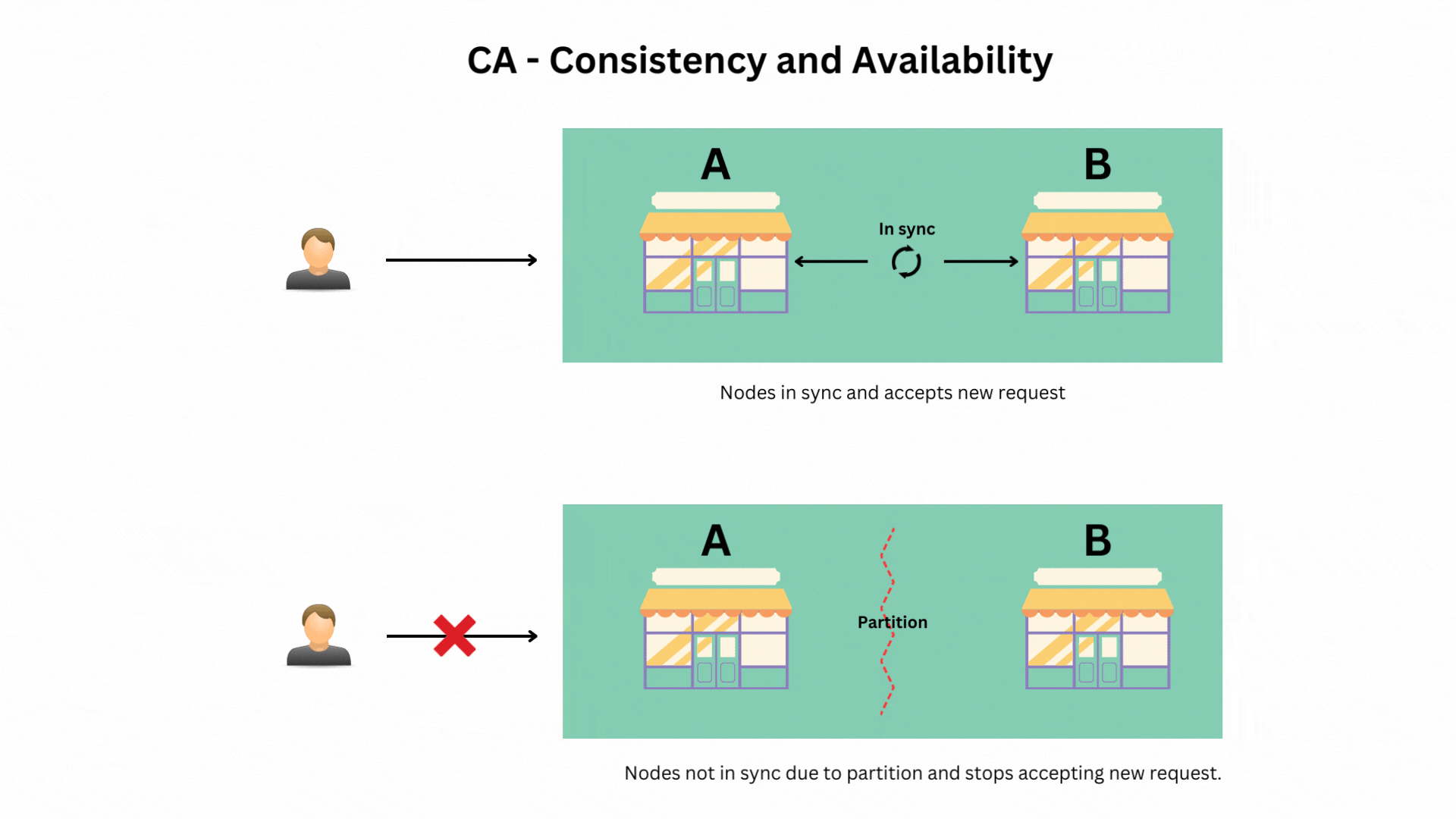
Why CA Systems Are Rare in Distributed Environments:
In distributed systems, network partitions are inevitable due to the nature of network failures, latency, and unpredictable behavior across nodes. Therefore, most real-world distributed systems opt for either CP (Consistency and Partition Tolerance) or AP (Availability and Partition Tolerance) configurations, as they must handle the reality of partitions.
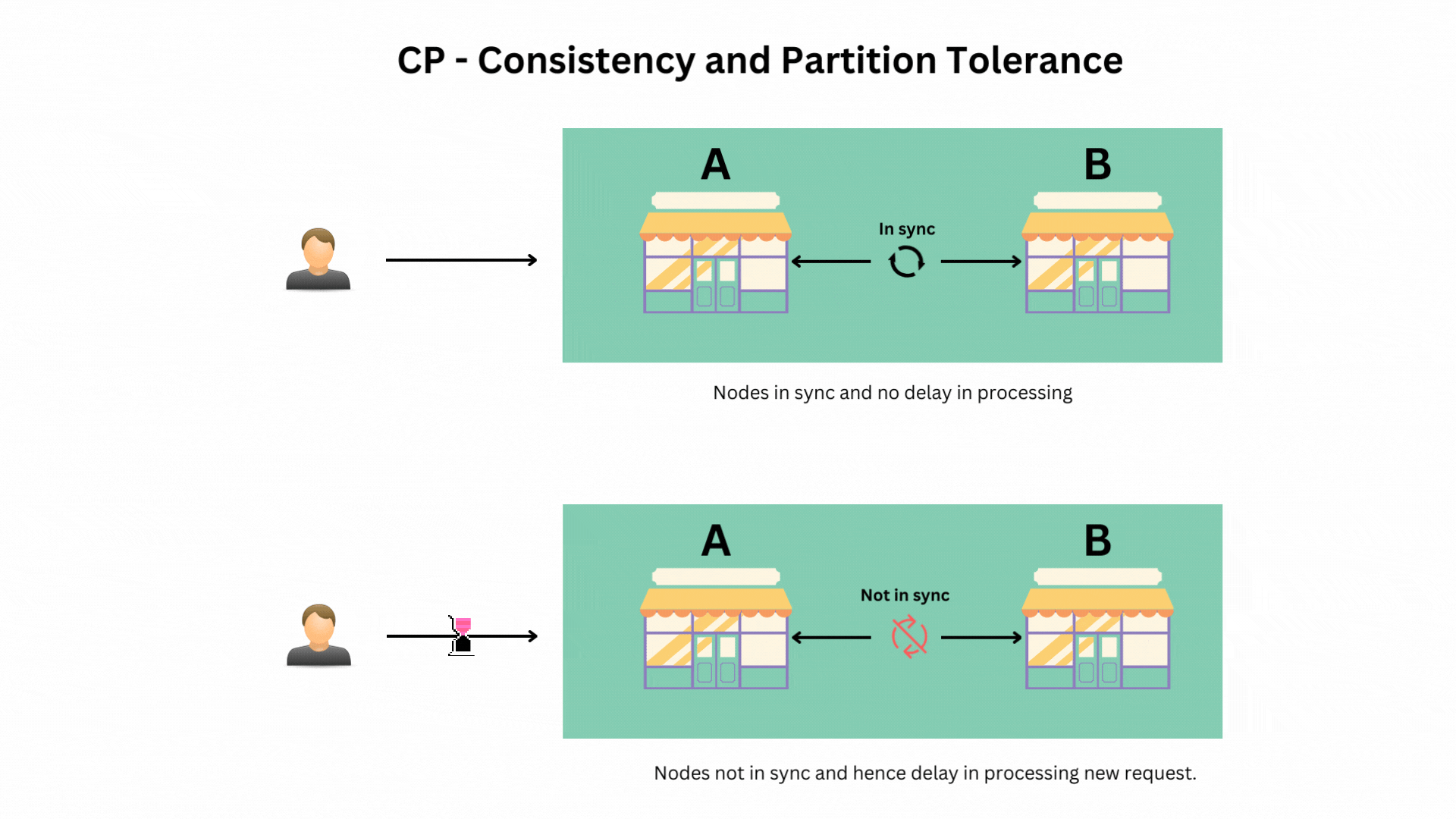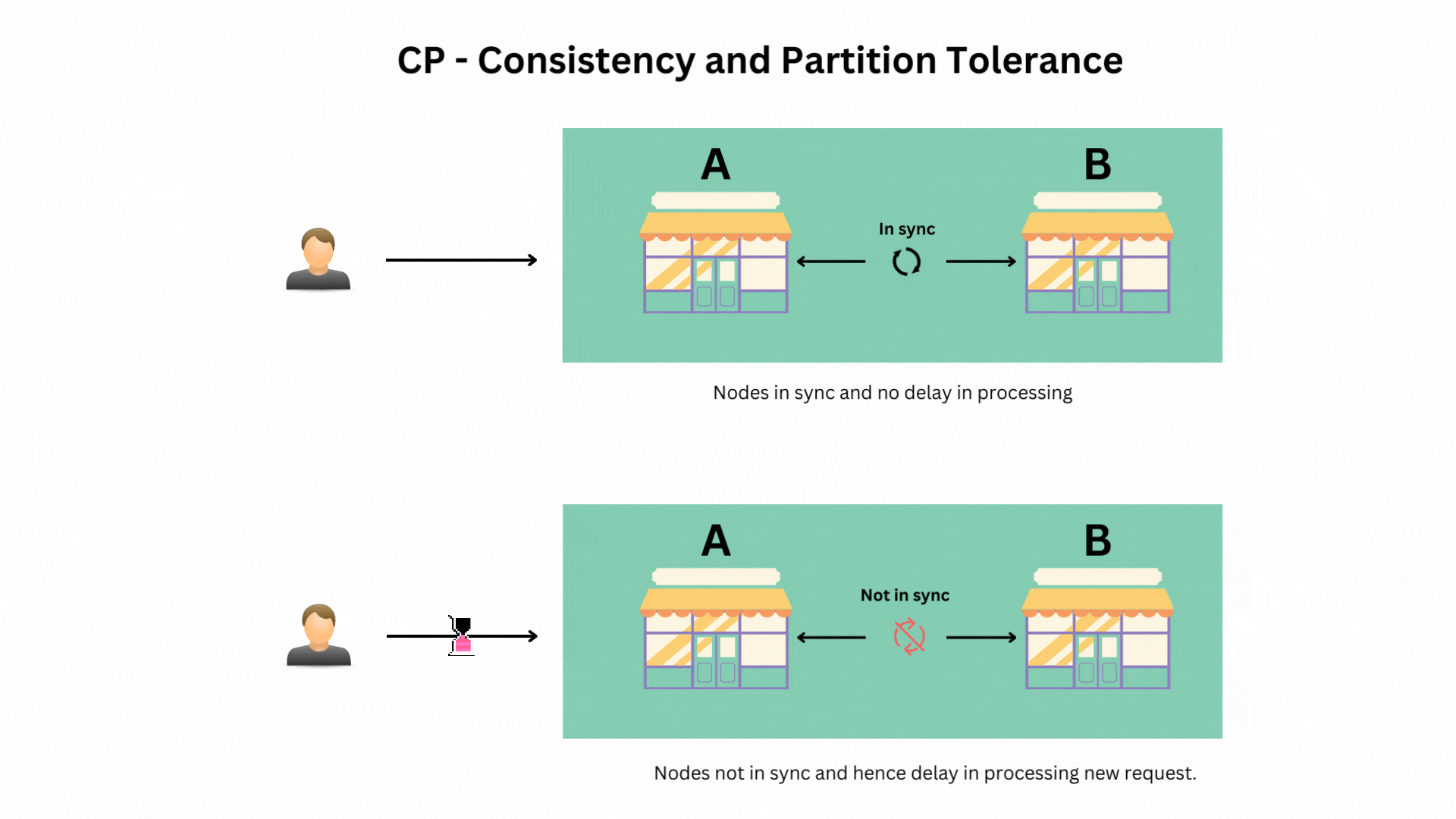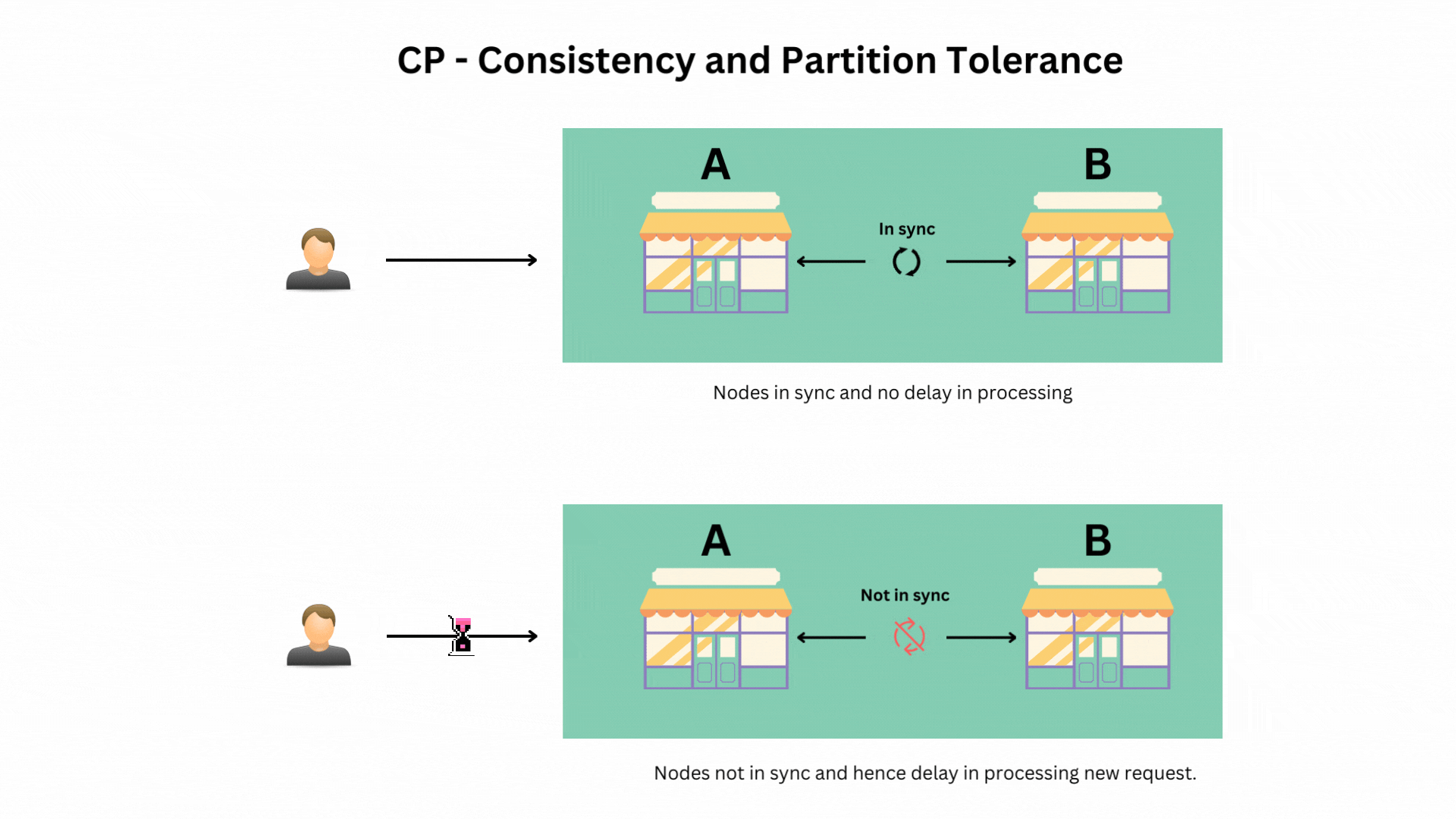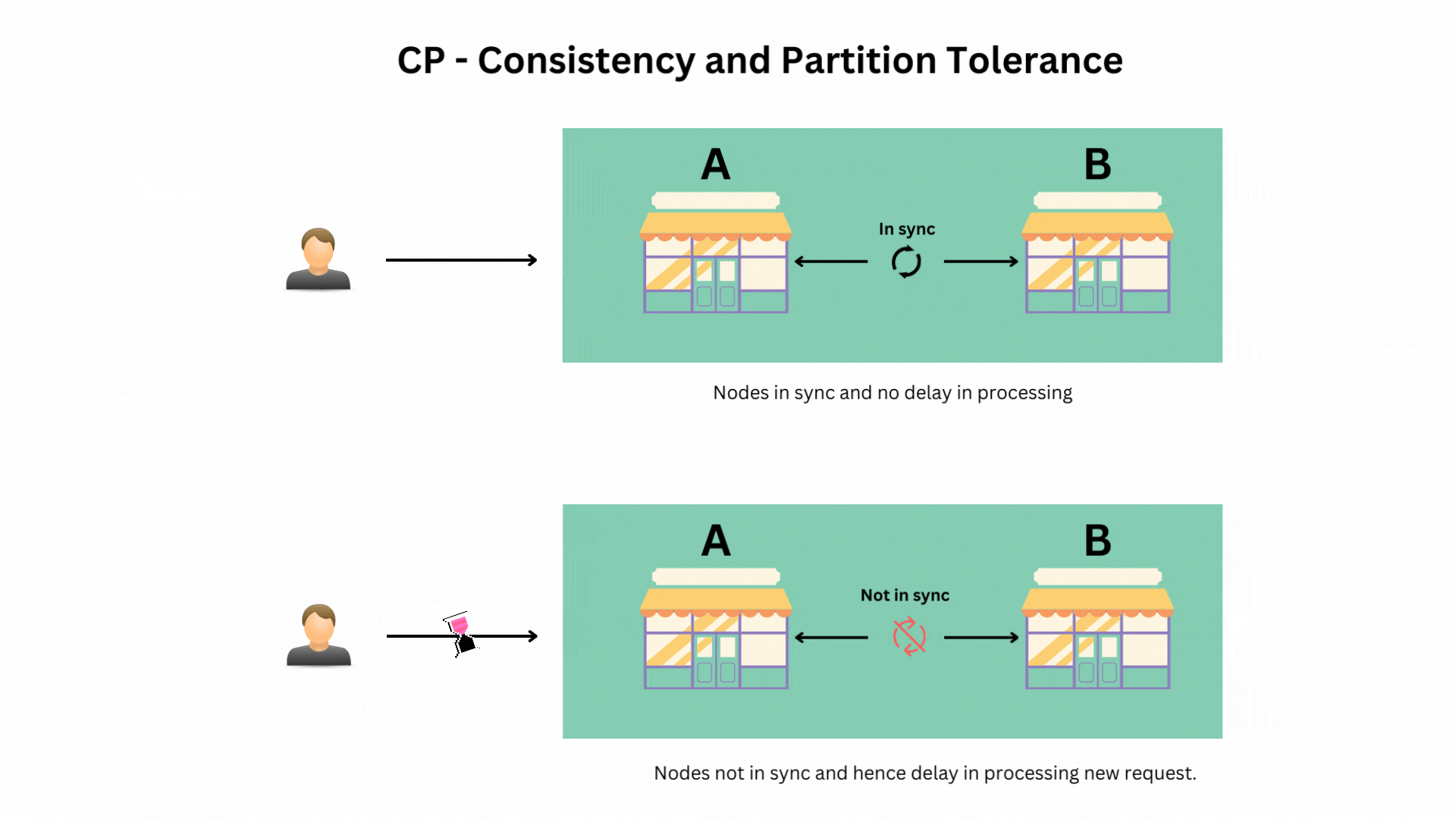
Scenario 2: Prioritizing Consistency and Partition Tolerance (CP)
Here, your system will ensure that data remains consistent even if the stores can’t communicate with each other. However, some stores might temporarily refuse to process new orders until they can synchronize.
- Example: Distributed databases like HBase, which might delay operations or return errors until data is consistent across all nodes.
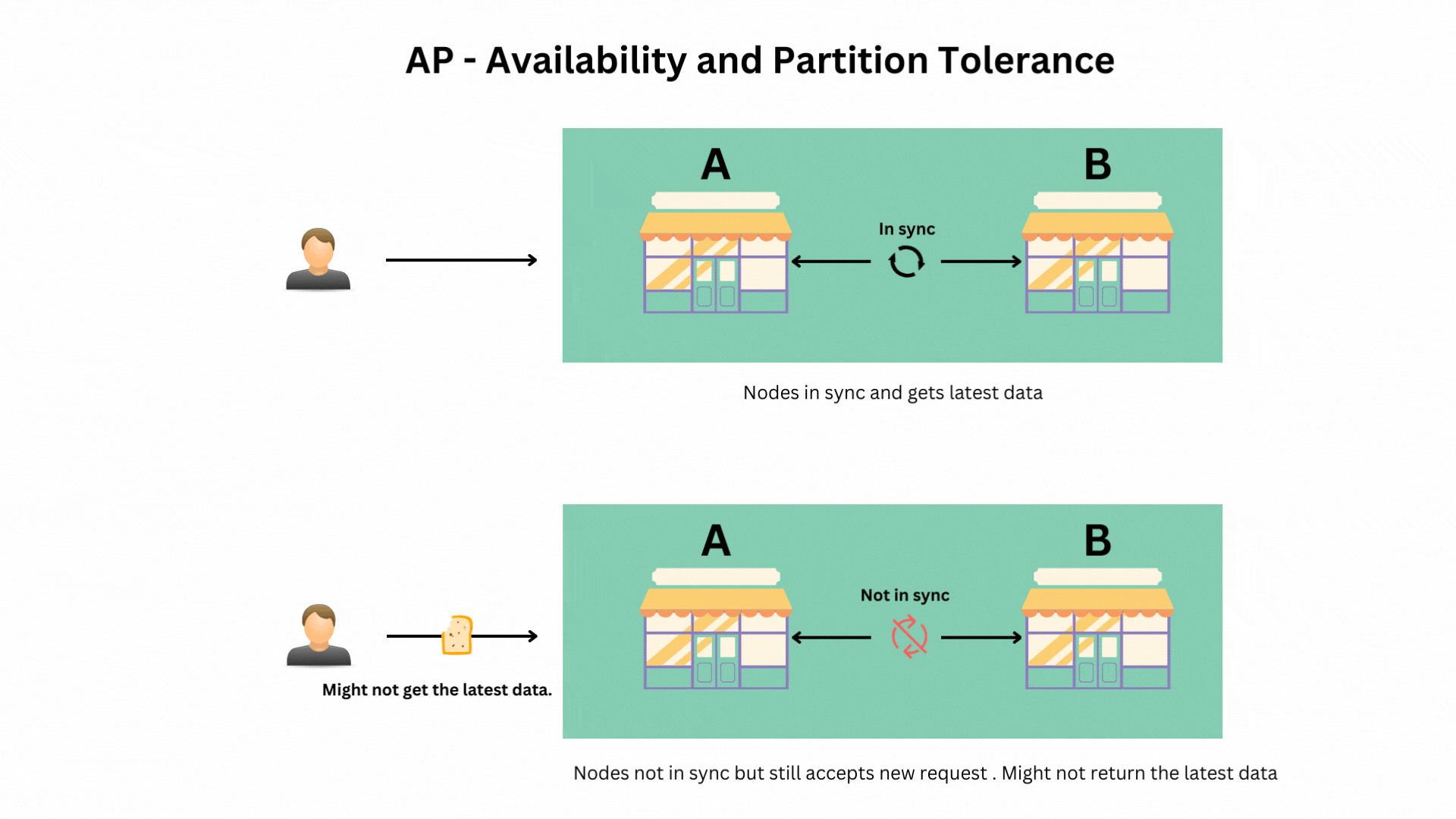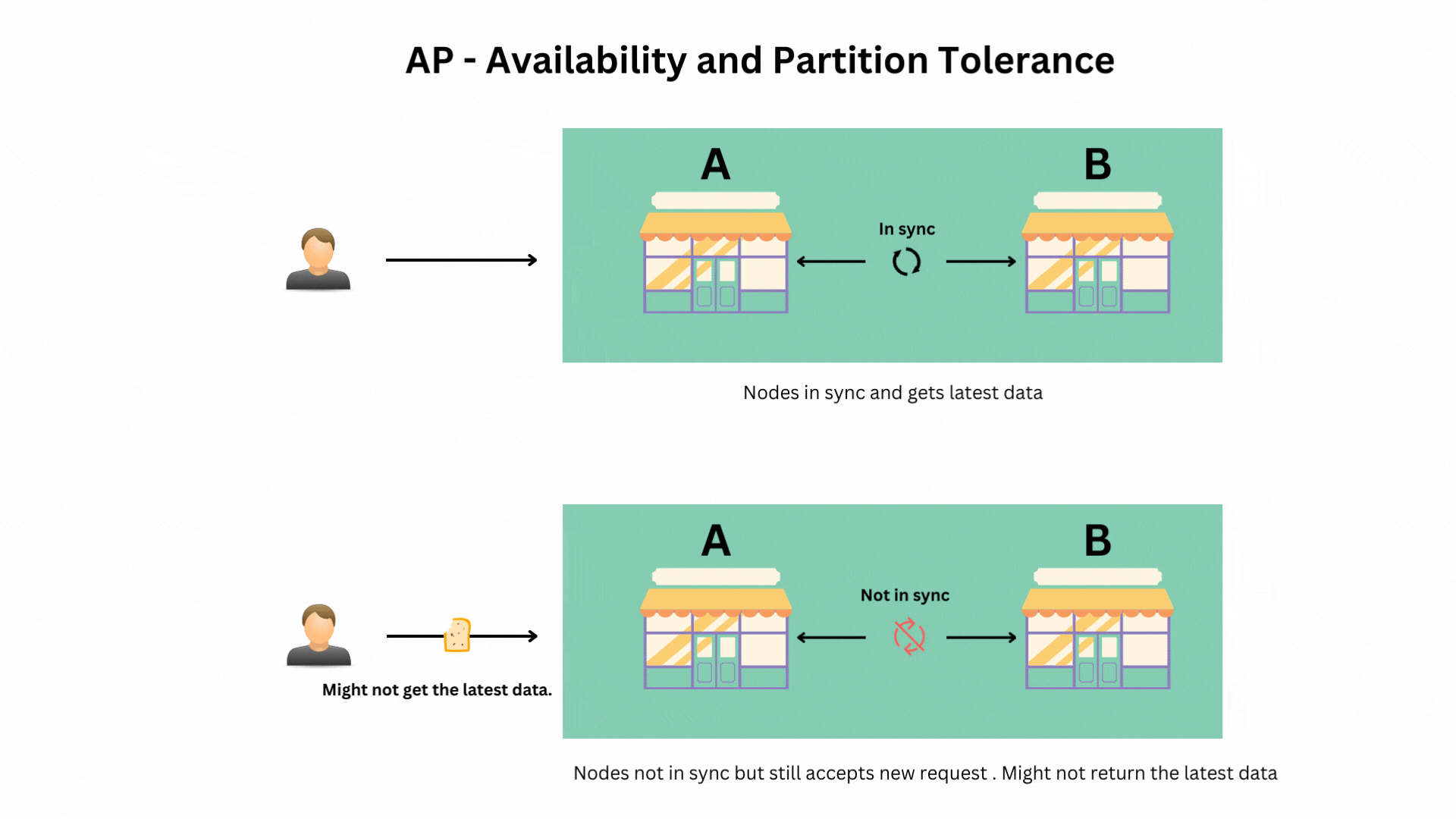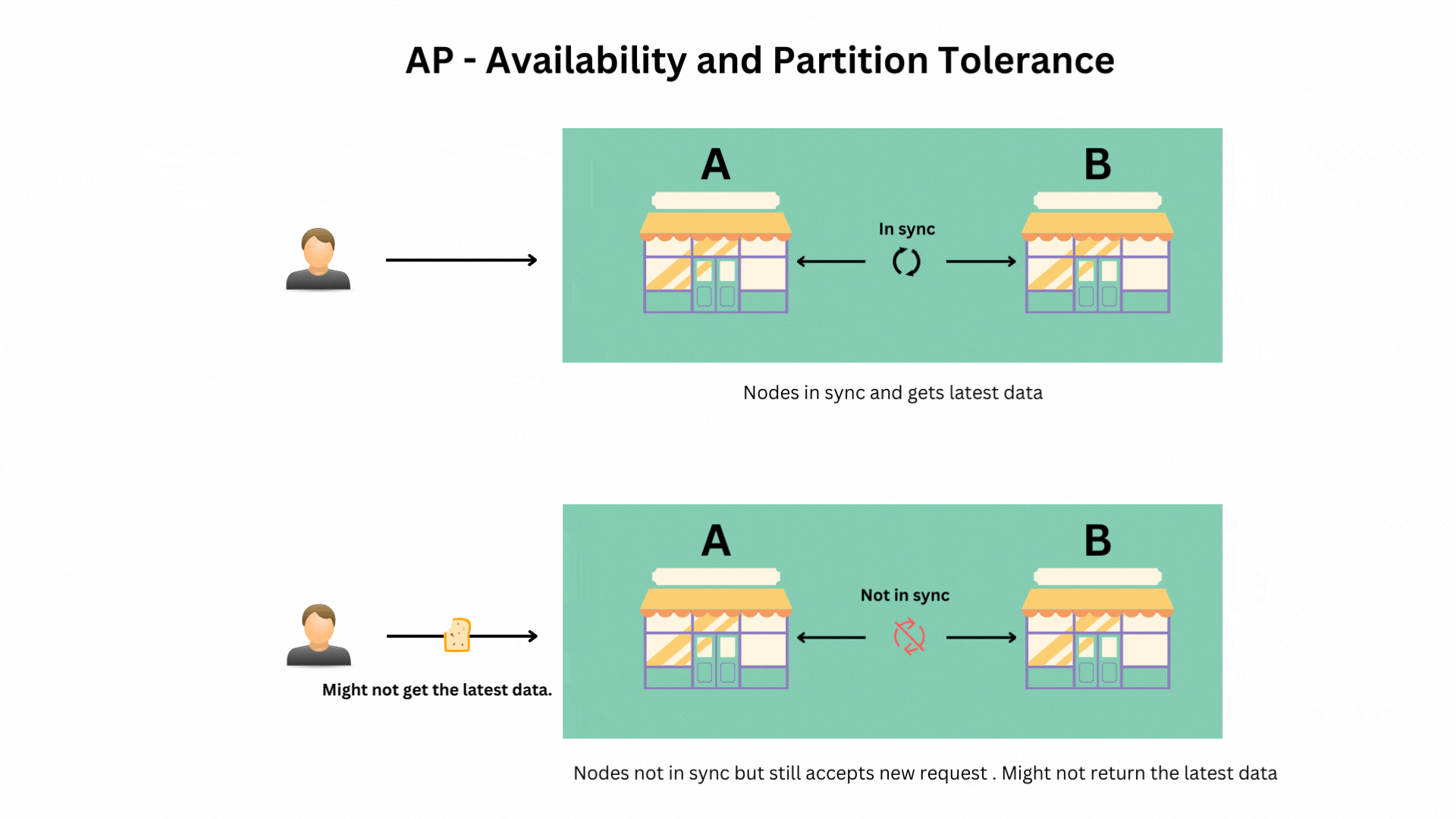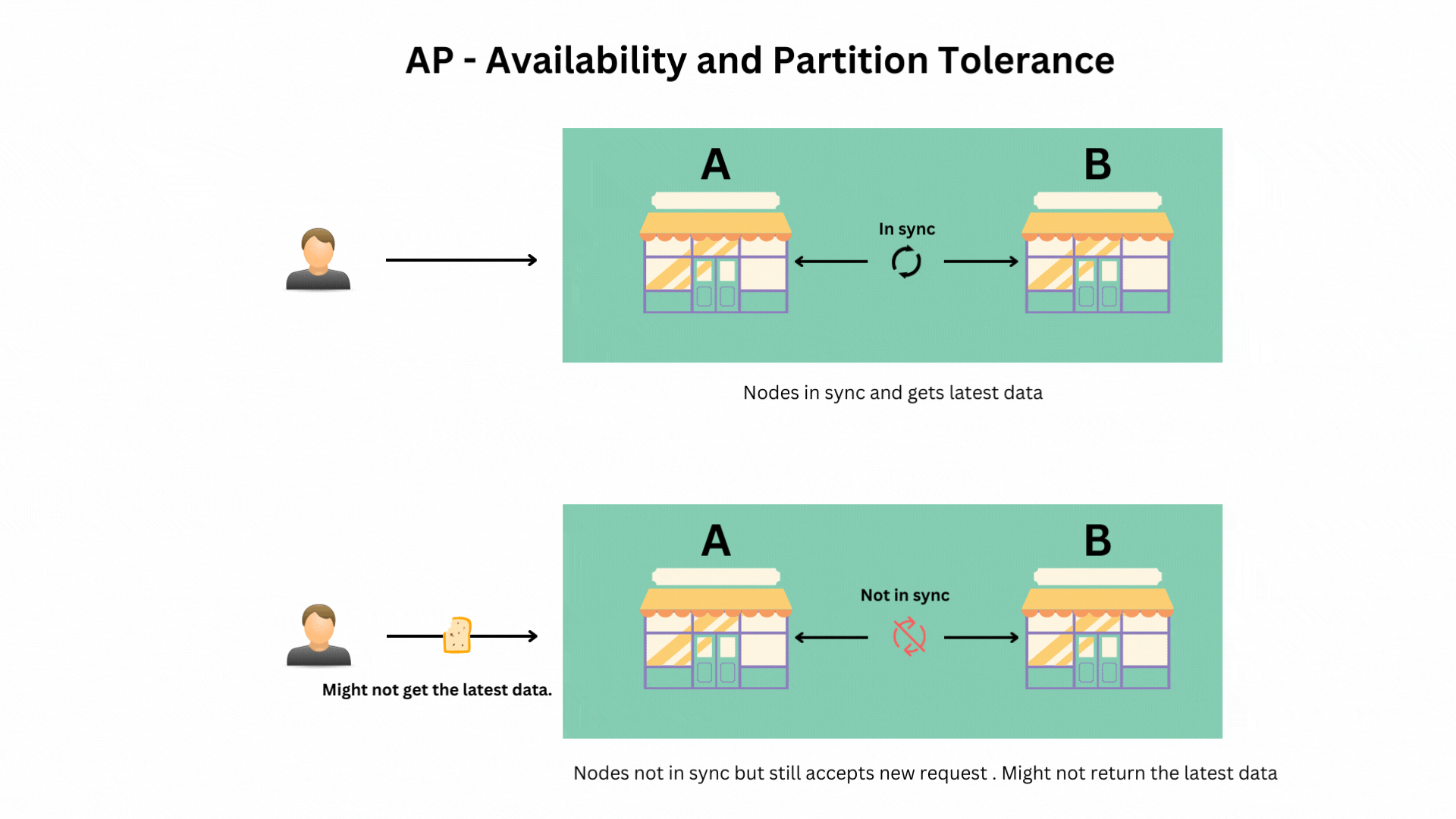
Scenario 3: Prioritizing Availability and Partition Tolerance (AP)
In this scenario, your stores continue operating and accepting orders even if they can’t communicate with each other, but some stores might show outdated information.
- Example: Systems like DynamoDB and Cassandra, which prioritize availability and partition tolerance but might return slightly outdated data under certain conditions (eventual consistency).
Applying the CAP Theorem to Database Tuning
The CAP theorem presents a challenging trade-off for distributed databases, but it’s essential to understand that you can fine-tune your database systems to favor certain aspects of the CAP triangle based on your application’s needs. Let’s explore how you can tune popular databases like MySQL, PostgreSQL, and Redis to achieve different CAP guarantees.
MySQL Tuning for CAP Theorem
Consistency and Availability (CA):
- Replication: MySQL’s primary-secondary (master-slave) replication can be configured for strong consistency using synchronous replication (e.g., Galera Cluster). This ensures that writes are only acknowledged when all replicas have applied the changes, maintaining consistency across nodes.
- InnoDB Engine: Use the InnoDB storage engine, which supports ACID transactions. This ensures that data remains consistent even during failures.
- Write Durability: Configure
innodb_flush_log_at_trx_committo1to ensure that every transaction is immediately written to disk. While this boosts consistency, it can slightly impact performance. - Failover Handling: Implement automatic failover mechanisms to maintain high availability, but be cautious of split-brain scenarios that can compromise consistency.
Partition Tolerance and Consistency (CP):
- Galera Cluster: Galera Cluster is known for providing strong consistency and partition tolerance. However, this comes at the cost of availability during network partitions, as the cluster may delay or block writes to maintain data integrity.
- Network Timeout Adjustments: Tweak settings like
net_read_timeoutandnet_write_timeoutto ensure that the system can handle network delays and partitions while maintaining consistency.
Availability and Partition Tolerance (AP):
- Asynchronous Replication: For better availability and partition tolerance, configure MySQL with asynchronous replication. This allows nodes to continue operating even if they can’t communicate, though the data may not be fully synchronized, leading to eventual consistency.
- Read Replicas: Enhance availability by setting up read replicas. This way, queries can be served from replicas even if the primary node becomes unavailable.
PostgreSQL Tuning for CAP Theorem
Consistency and Availability (CA):
- Synchronous Replication: PostgreSQL supports synchronous replication, where transactions are committed only after data is written to both the primary and replica nodes, ensuring consistency.
- ACID Transactions: PostgreSQL’s default transactional behavior guarantees data consistency. To enhance this, ensure that
fsyncis enabled, forcing data to be written to disk. - High Availability (HA): Use HA tools like Patroni or PgBouncer to manage failover while preserving consistency.
Partition Tolerance and Consistency (CP):
- Multi-Master Replication: Implement multi-master replication using tools like Bucardo or BDR (Bi-Directional Replication) to maintain consistency across nodes during partitions. However, this might reduce availability as some requests could be delayed or denied.
- Timeout Configuration: Tuning
statement_timeoutandlock_timeoutsettings can help manage partition tolerance, ensuring that the system gracefully handles network issues while preserving consistency.
Availability and Partition Tolerance (AP):
- Asynchronous Replication: PostgreSQL can be configured for high availability through asynchronous replication, allowing the system to serve requests even during network partitions. However, this setup will only provide eventual consistency.
- Connection Pooling: Enhance availability and performance by using connection pooling with tools like PgBouncer, which can handle a large number of connections efficiently.
Redis Tuning for CAP Theorem
Consistency and Availability (CA):
- Redis Sentinel: Redis Sentinel manages failovers and promotes replicas to master when the original master fails. This setup prioritizes availability and consistency by ensuring that operations can continue even after a failure.
- Synchronous Replication: To enforce consistency, use Redis commands like WAIT, which ensures that writes are replicated to a certain number of replicas before returning success.
Partition Tolerance and Consistency (CP):
- Redis Cluster: Redis Cluster offers partition tolerance and consistency by distributing data across multiple nodes. However, it may sacrifice availability during a network partition.
- Quorum Writes: You can achieve strong consistency across partitions by using quorum-based writes with the WAIT command, ensuring that data is replicated to a majority of nodes.
Availability and Partition Tolerance (AP):
- Asynchronous Replication: To prioritize availability during network partitions, Redis can be configured with asynchronous replication. This setup ensures that the system continues to accept writes, though it may lead to eventual consistency.
- Read Replicas: Enhance availability by enabling read replicas, allowing data to be read from replicas even if the master node is temporarily unavailable.
Conclusion: Making the Right Trade-offs
The CAP theorem is a guiding principle in distributed system design, illustrating the trade-offs between consistency, availability, and partition tolerance. By understanding the needs of your application and carefully tuning your database systems, you can strike the right balance among these guarantees. Whether you prioritize immediate consistency, high availability, or resilience against network partitions, the right configuration can ensure that your distributed system performs optimally in line with your goals.

